





 Рейтинг: 4.0/5.0 (1868 проголосовавших)
Рейтинг: 4.0/5.0 (1868 проголосовавших)Категория: Бланки/Образцы
Российской академии наук
Н.С.Байгарова, Ю.А.Бухштаб, Н.Н.Евтеева, Д.А.Корягин
Некоторые подходы к организации содержательного
поиска изображений и видеоинформации
В работе рассматриваются способы решения проблемы содержательного описания изображения на различных уровнях абстракции.
Технология доступа к коллекциям изображений и видеофильмов по визуальному содержанию реализуется на базе сопоставления им набора визуальных примитивов и определением количественной оценки близости изображений по значениям примитивов.
The paper discusses various questions connected with content-based visual information description on differen levels of abstraction. The access technology for image and video collections is developed on the base of corresponding visual primitives. Once the distance between the template image and each target image is computed, target images can be ranked in order of their similarity with the template image.
Работа выполнена при финансовой поддержке Российского фонда фундаментальных исследований, грант N 01-01-00267.
Предлагаемые подходы ориентированы на решение проблемы обеспечения доступа к современным электронным коллекциям изображений и видеоматериалов с использованием различных средств - как текстовых описаний, так и характеристик визуального содержания, простейших типа цветовой гаммы, и более сложных, связанных с распознаванием образов, наиболее интересных для предметной области.
До недавнегонего времени традиционным считался поиск визуальной информации, опирающийся на индексирование текстовых описаний, ассоциированных с изображением или фильмом. Однако поиск по названию, авторам, теме, словам описания содержания и по другой текстовой информации, ассоциированной с изображениями коллекции, представляется недостаточным. Неоднозначность соответствия между визуальным содержанием и текстовым описанием снижает показатели точности и полноты поиска.
Визуальные примитивы и механизм поиска по образцу
Для организации электронных библиотек, связанных с визуальными данными, требуются методы создания и использования поисковых образов, отражающих визуальное содержание изображений. Методы распознавания образов и понимания сцены в настоящее время из-за отсутствия эффективных универсальных алгоритмов применяются в узких предметных областях. Современная универсальная технология доступа к коллекциям изображений связана с сопоставлением изображению набора визуальных примитивов (характеристик цвета, формы, текстуры, а для видео еще и параметров движения сцены и объектов) и определением количественной оценки близости изображений по значениям примитивов[7, 14, 15, 16].
Визуальные примитивы - это характеристики изображения, которые автоматически вычисляются по оцифрованным визуальным данным, позволяют эффективно индексировать их и обрабатывать запросы с использованием визуальных свойств изображения. Поисковый образ изображения, сгенерированный из визуальных примитивов, невелик по размеру в сравнении с самим изображением и удобен для организации поиска. Вычисление подобия изображений заменяет принятую в традиционных СУБД операцию установления соответствия запросу. Хотя запросом в такой системе может быть описание набора примитивов, более удобен запросный механизм поиска по образцу, когда система отыскивает изображения, визуально похожие на предоставленный образец. Система анализирует образец аналогично тому, как это делается при составлении поисковых образов изображенийбазы. Вычисление подобия изображения-образца изображениям коллекции осуществляется на основаниисравнения значений отдельных визуальных примитивов, при этом система определяет меру их отличия, а затем сортирует изображения базы в соответствии с близостью к образцу по всем параметрам, с учетом указываемой в запросе степени важности каждого параметра. Поиск на таком уровне абстракции не предполагает идентификацию объектов.Скажем, если в качестве образца взято изображение собаки, то система будет искать изображения, похожие на образец по цветовой гамме, композиции, наличию определенных форм и т.п. но нет никакой гарантии, что среди них окажется изображение именно этого животного. Тем не менее, метод поиска по образцу на основании визуальных примитивов представляется на сегодняшний день достаточно эффективным и универсальным средством доступа к коллекциям оцифрованных изображений.
3. Методы анализа изображений
Различными группами исследователей уже накоплен определенный опыт реализации алгоритмов, позволяющих автоматически описывать изображения в терминах простых вычислимых визуальных свойств, а также определять меру их отличия. Авторами был подготовлен обзор этих алгоритмов [8].
Наши текущие исследования в этой области направлены на дальнейшее развитие методов вычисления и сравнения визуальных примитивов. Реализован метод количественной оценки близости статичных изображений по их цветовым гистограммам. Решена задача пространственного сегментирования изображения. Разработан и реализован алгоритм, осуществляющий вычисление параметров форм для выделенных объектов картинки и сравнение форм по их параметрам. Проводятся работы и имеются результаты, которые позволят выполнять локальное индексирование, отражающее распределение на изображении цветовых множеств. С целью вычисления измерений текстур исследуются возможности использования метода функций Габора и характеристик матрицы взаиморасположения оттенков серого цвета. (Методы обработки текстур изложены в [10, 20, 22, 26].)
3.1. Цветовые гистограммы
Метод цветовых гистограмм – наиболее популярный из методов, использующих цветовые характеристики для индексирования изображений. Возможно также использование таких показателей, как средний или основной цвета, а также множества цветов; эти характеристики имеет смысл использовать для локального индексирования областей изображения [11, 19, 20, 21].
Идея метода цветовых гистограмм для индексирования и сравнения изображений сводится к следующему. Все множество цветов разбивается на набор непересекающихся, полностью покрывающих его подмножеств Vi, 0<=i<N. Будем называть такое разбиение множества цветов базовой палитрой. Для изображения формируется гистограмма, отражающая долю каждого подмножества цветов в общей цветовой гамме изображения - массив H[i]=N[i]/ ? N[i], где N[i] - число точек с цветом из множества Vi. Для сравнения гистограмм вводится понятие расстояния между ними. Известны различные способы построения и сравнения цветовых гистограмм [1, 2, 8, 19, 20], отличающиеся между собой изначальной цветовой схемой(RGB, CMY, HSV, grayscale и т. д.), размерностью гистограммыиопределением расстояния между гистограммами.
В данной работе реализовано несколько модификаций метода, использующих разные способы квантования множества цветов и вычисления расстояния между гистограммами. Используются две базовые палитры и, следовательно, два метода построения гистограммы.
1) Разбиение RGB-цветов по яркости.
В базовой палитре Vi (0<=i<N) определяется как множество цветов C. C ?Vi?i/N*Imax<=I(C)< (i+1)/N*Imax, где I(C) – интенсивность цвета C, нормализованная так, что 0<=I(C)<Imax. Интенсивность вычисляется по классической формуле:
I(C)=0.3*R(C)+0.59*G(C)+0.11*B(C),где R, G и B – красная, зеленая и синяя компоненты цвета C. Imax=256; 0<=I(C)<256. В частности, для черно-белых полутоновых изображений наNподмножеств разбивается исходное множество оттенков. Значение N выбиралось практически произвольно, сейчас установлено N=16.
Для сравнения гистограмм вводится понятие расстояния между ними - сумма модулей разности соответствующих элементов гистограмм. Некоторое усовершенствование метода достигается при вычислении расстояния на основании поэлементного сравнения гистограмм с учетом соседних элементов. Для каждого элемента гистограммы первого изображения вычисляется не одна, а три разности:
R3(i)=?H1[i]-H2[i+1]?(для i=0 и i=N вместо невычислимых разностей подставляются заведомо большие значения), итоговое же расстояние равно:
Этот способ не годится для произвольной базовой палитры, т. к. предполагает строгую упорядоченность множества цветов, как в случае с разбиением по яркости. Заметим, что так определенное S не является расстоянием в математическом смысле из-за несимметричности (нельзя гарантировать, что S(H1,H2)= S(H2,H1)). Основное преимущество алгоритма состоит в том, что он слабо чувствителен к изменению освещенности, что ощутимо улучшает результаты его применения на широком классе изображений.
Этот метод построения гистограмм наиболее эффективен для черно-белых полутоновых изображений. Для цветных RGB-изображений лучшие результаты дает другой способ.
2) Разбиение RGB-цветов по прямоугольным параллелепипедам.
Цветовое RGB-пространство рассматривается как трехмерный куб, каждая ось которого соответствует одному из трех основных цветов (красному, зеленому или синему), деления на осях пронумерованы от 0 до 255 (большее значение соответствует большей интенсивности цвета). При таком рассмотрении любой цвет RGB-изображения может быть представлен точкой куба. Для построения цветовой гистограммы каждая сторона делится на n (n=4) равных интервалов, соответственно RGB-куб делится на N (N=64) прямоугольных параллелепипедов. Vi – множество цветов, все компоненты которых попадают в определенные интервалы. Гистограмма изображения отражает распределение точек RGB-пространства, соответствующих цветам пикселов изображения, по параллелепипедам.
Выбор размерности гистограммы определялся из следующих соображений. При n=2 (N=8) считались бы одинаковыми, например, <126,128,126> и <0, 255, 0>, что, естественно, недопустимо. Установка n=8 (N=512) приводит к тому, что базовая палитра становится более строгой, чем 8-битная. Такая точность не только автоматически дает некорректную обработку 256-цветных изображений, но и на остальных изображениях приводит к неестественным результатам. Очевидно, что при росте n ситуация только ухудшается. Поэтому было установлено n=4.
В качестве расстояния между гистограммами используется покомпонентная сумма модулей разности между ними. Несмотря на предельную простоту подхода, он показывает довольно стабильные результаты. Распознаются схожие по цветовой гамме серии картинок, если они имеются в базе.
Более точное сравнение изображений достигается с помощью техники квадродеревьев, когда методы вычисления и сравнения цветовых гистограмм применяются не ко всему изображению, а к его четверти (одной шестнадцатой и т. д.). Сейчас программа позволяет работать не только с полными изображениями, но и с их разбиением на четверти. Для реализации этой возможности, при построении гистограммы автоматически считаются и гистограммы всех четырех квадрантов изображения. Сравнение изображений основывается на расстоянии, определенном как Евклидово в пространстве расстояний между гистограммами их частей - вместо вычисления расстояния между полными гистограммами, рассчитываются расстояния между четвертями, итоговым результатом считается корень из суммы их квадратов. Этот метод дает результат, семантически отличный от других вариантов: изображения, отличные только по взаимному расположению похожих по цвету объектов, считаются различными, а не практически идентичными, как было бы без использования этой техники. Целесообразность ее применения определяется значением для пользователя расположения на картинке-образце определенных цветовых областей.
3.2. Объекты изображения
Пространственное сегментирование изображения может осуществляться автоматически, когда выделяются области с некими общими свойствами - одинаковыми или сильно схожими значениями того или иного примитива. Полученные в результате области характеризуются расположением на изображении и размерами. Кроме того, они связываются со значениями примитивов – характеристиками формы, цвета, текстуры.
Контур - граница объекта - представляет собой замкнутую последовательность точек (xs, ys),где1<=s<=N. Удобно считать, что (xs+N, ys+N) = (xs, ys). Задача выявления контуров связана с локализацией на изображении резких перепадов яркости цвета или изменений параметров, характеризующих текстуру.
Определение границ объектов изображения выполняется нами по следующей схеме: цветное изображение переводитсяв черно-белое полутоновое и сглаживается, осуществляется пространственное дифференцирование - вычисляется градиент функции интенсивности в каждой точке изображения и, наконец, подавляются значения меньше установленного порога. За основу взят метод Собеля[23], использующий для вычисления градиента первого порядка функции интенсивности специальные ядра, известные как «операторы Собеля»:
Ядра применяются к каждому пикселу изображения: он помещается в центр ядра, и значения интенсивности в соседних точках умножаются на соответствующие коэффициенты ядра, после чего полученные значения суммируются. Х- оператор Собеля, примененный к 3х3 матрице исходного изображения, дает величину горизонтальной составляющей градиента интенсивности в центральной точке этой матрицы, а Y-оператор Собеля дает величину вертикальной составляющей градиента. Коэффициенты ядра выбраны так, чтобы при его применении одновременно выполнялось сглаживание в одном направлении и вычисление пространственной производной – в другом.
Величина градиента определяется как квадратный корень из суммы квадратов значений горизонтальной и вертикальной составляющих градиента.
В результате образуется массив чисел, характеризующих изменения яркости в различных точках изображения. Затем выполняется операция сравнения с порогом и определяется положение элементов изображения с наиболее сильными перепадами яркости. Выбор порога является одним из ключевых вопросов выделения перепадов. В нашей реализации он отличается от оригинального метода Собеля. В качестве основного порога берется средняя для изображения величина градиента - Smid. Для достаточно большого изображения с малым числом точек, обладающих сильным перепадом яркости, данной пороговой величины недостаточно, т.к. оказывается весьма сильным влияние шума. Для ликвидации этой проблемы для каждой точки изображения считается величинаSlocal, равная средней величине градиента в области 3х3 вокруг анализируемой точки. Пороговое условие выглядит так:
(G(i, j)>=Smid) AND (Slocal >= Smid)
В результате обработки получается бинарная матрица, где единицам соответствуют точки со значительным перепадом яркости, нулям – все остальные. В качестве дополнительной меры в борьбе с шумом и
ликвидации возможных разрывов в контурах применяются морфологические операции.
Следующий этап – сегментация изображения. Целью сегментации является выделение на изображении контуров объектов. В бинарной матрице единицами представлены точки, принадлежащие искусственно утолщенным на предыдущем этапе границам объектов. Для выделения границы одного объекта в матрице по определенному алгоритму ищется элемент, равный единице, не отнесенный ранее ни к какому другому объекту; далее считается, что все соседние элементы, равные единице, также принадлежат этому объекту; и т. д. Для выделения точек внешнего контура используется обход полученного объекта по внешней его стороне, начиная с нижней левой точки объекта и заканчивая ею же. Обход точек ведется последовательно против часовой стрелки. В результате получаем массив точек, образующий замкнутый контур объекта. Из него равномерно выбирается 128 точек (xs, ys), где 1<=s<=128, которые используются для вычисления предназначенных для индексирования характеристик формы. (Небольшие объекты исключаются из рассмотрения.)
3.3. Характеристики формы
Существует практика использования формы объектов для индексирования изображений с целью их дальнейшего сравнения [2, 8, 26].
Для точек выделенного контура объекта в данной работе вводятся две функции.
Ф
ункция расстояния от точек контура до центра фигуры:
где (xc=? xs /N, yc=? ys/N ) - центр масс контура
Для обеспечения инвариантности относительно поворотов и масштаба, выполняется нормирование величин, а в качестве начальной точки контура берется та, расстояние до центра от которой наименьшее, соответственно упорядочиваются элементы векторов.
Предлагается способ сравнения форм объектов на основании вычисления общего расстояния между парами соотвествующих векторов.
Определение объекта изображения на основании близких значений интенсивности соседних точек позволяет довольно точно характеризовать выделенную область изображения с помощью такого показателя, как средний цвет точек области. Таким образом, для выделенных объектов могут быть определены и включены в индекс такие характеристики, как расположение, размеры, измерения формы, средний цвет.
4. Методы анализа видеоданных
4.1. Временное сегментирование видеофильма
В связи с большим объемом видео-файлов для организации эффективного поиска данных с удовлетворительными показателями полноты и точности, а также для обеспечения быстрого предоставления пользователю релевантной информации имеет смысл индексировать каждый фильм не как единое целое, а как последовательность логически самостоятельных частей — видеофрагментов [15]. Задача сводится к определению границ видеофрагментов, они могут быть связаны с точками монтажа, изменением положения снимающей камеры и т.п. Формально задачу можно поставить так: на вход подается упорядоченный набор кадров, необходимо выделить из них последовательность номеров, каждый из которых соответствует началу нового фрагмента.Временное сегментирование может выполняться путем автоматического анализа изображения, соответствующие приемы известны [3, 6, 12, 25]. Достаточно эффективны для выделения кадров, на которых происходит значительное изменение видеоизображения, методы, основывающиеся на вычислении низкоуровневых характеристик изображения.
Предлагается алгоритм, основанный на сравнении цветовых гистограмм соседних кадров. Система вычисляет цветовую гистограмму очередного кадра и сравнивает с предыдущей. Построение и сравнение гистограмм осуществляются идентично работе со статичными изображениями. Есть дополнительная возможность “выравнивания” гистограмм, применение которой имеет смысл только в случае разбиения множества цветов по яркости. Целью ее является приведение гистограммы к виду, при котором верно:
После построения гистограммы определяется ее медиана, т. е. такое k, чтоПосле этого все точки гистограммы пересчитываются, исходя из соотношения:
H'[i]=(H[k/(N/2)*i]+ H[k/(N/2)*i+1])/2, при 0<=i<N/2 и аналогичного выражения для N/2<=i<N. Оригинальная гистограмма заменяется на H'. Потребность такой обработки объясняется тем, что во многих реальных образцах видео (особенно черно-белых и/или плохого качества) часто встречаются практически идентичные соседние кадры, отличающиеся только по яркости среднего освещения. Семантически они должны попадать в один фрагмент, но их первоначальные гистограммы могут существенно различаться, что и приводит к необходимости выравнивания. Прием не дает полного решения проблемы, но, по крайней мере, существенно улучшает результаты на широком классе изображений.
Результатом сравнения гистограмм последовательных кадров является массив R[i] чисел от 0 до 2, где i-ый компонент – расстояние между гистограммами i-ого и (i+1)-ого кадров. Опираясь на эти данные, фильм разбивается на фрагменты. Граница фрагментов считается обнаруженной, если разница гистограмм рассматриваемых соседних кадров выше некоторого абсолютного порога и одновременно в определенное число раз превышает среднее значение разницы гистограмм соседних кадров, посчитанное по кадрам от начала выделяемого фрагмента (относительный порог).
Попытка ограничиться абсолютным порогом L не привела к успеху. Значение порога, дающее желаемые результаты, существенно зависит от качества записи фильма, динамики его связных фрагментов и средней освещенности, а эти характеристики могут быть различны в разных фрагментах одного и того же фильма (т. е. для их вычисления потребуются уже готовые результаты временной сегментации), а кроме того, определение, например, качества записи - трудная задача, и зависимость от нее неизбежно внесет дополнительную погрешность в итоговый результат. Аналогично, не удалось решить задачу и введением относительного порога, т. е. такого M, что при R[i]>M*?R[j]/(i-1-k) (сумма берется от k до i-1, k-й кадр – первый в текущем фрагменте), (i+1)-й кадр считается началом следующего фрагмента. Проблема заключается в возможности практически полного совпадения первых нескольких гистограмм фрагмента и минимального отличия от них следующей - условие порога будет выполнено, и программа выдаст лишний фрагмент. Наиболее эффективной оказалась комбинация этих подходов, т. е. для принятия решения о том, что (i+1)-й кадр – начало нового фрагмента требуется выполнение обоих условий:
Результаты сегментирования, разумеется, сильно зависят от выбора параметров. Они установлены эмпирически для достижения приемлемых результатов с точки зрения минимизации числа ошибок, связанных с обнаружением ложной границы и пропуском действительной. (При уменьшении вероятности одной из ошибок, неизбежно повышается вероятность другой.) Текущие значения L=0.15 иM=3 подобраны так, чтобы ложные обнаружения встречались примерно на порядок чаще, чем пропуск переходов. Вызвано это тем, что на“двойном” видеофрагменте невозможно корректно вычислить оптический поток, что является одной из главных целей временного сегментирования, в то время как два фрагмента вместо одного дают лишь некоторое увеличение требуемых для дальнейшей обработки ресурсов.
Для тестирования программы использовались видеофильмы, взятые из различных источников, разного качества. Все фильмы разбиты на несколько непересекающихся групп, результаты внутри которых были более или менее одинаковы. Приводим усредненные результаты, отражающие процент ошибок, допускаемых различными методами временной сегментации на различных типах видеофрагментов.
Цветное видео Черно-белое видео Цветное видео Черно-белое видео1 - Палитра разбивается по интенсивности.
2 - Палитра разбивается на RGB-параллелепипеды.
3 – Квадродерево & палитра разбивается по интенсивности.
4 – Квадродерево & палитра разбивается на RGB-параллелепипеды.
5 - Палитра разбивается по интенсивности, применяется усложненная формула расстояния и выравнивание гистограмм.
(Процент ошибок – отношение числа ошибок к сумме ошибок и верно обнаруженных переходов, умноженное на 100%.)
4.2. Индексирование видеофрагментов
После того как видеопоток разбивается на фрагменты, из них выделяются для исследования ключевые стоп-кадры. Стратегия извлечения представительных стоп-кадров из каждого выделенного фрагмента может быть, например, такой[1]: если фрагмент короче секунды, берется один центральный кадр, для более длинных фрагментов берется по одному в секунду. Для каждого выделенного кадра вычисляются с целью индексирования визуальные примитивы: цветовые гистограммы, характеристики формы и цвета объектов изображения, измерения текстуры; для этого применяются те же методы, что и для анализа статичных изображений. Кроме того, представляется важным индексировать фрагмент также характеристиками движения камеры/сцены и движения объектов, определяемыми на основании совокупности кадров видеофрагмента[3, 6].
4.3. Вычисление оптического потока
Для индексирования видеоданных по движению применяется метод оптического потока. Он основан на том, что для видеофрагмента, содержащего некоторые объекты в движении, можно вычислить направление и величину скорости движения в каждой точке видеокадра. Известны разные алгоритмы вычисления оптического потока [9].















TinEye – поиск изображения по образцу и по цветовой схеме.
 Про поисковую систему TinEye хотел написать уже дано, но руки не доходили, а потом вообще забылось. И вот сегодня воспользовался одной из возможностью данного сервиса, по поиску изображения по цветовой схеме, о которой вы сможете прочитать дальше. Ну это не единственная функция поисковой системы TinEye.
Про поисковую систему TinEye хотел написать уже дано, но руки не доходили, а потом вообще забылось. И вот сегодня воспользовался одной из возможностью данного сервиса, по поиску изображения по цветовой схеме, о которой вы сможете прочитать дальше. Ну это не единственная функция поисковой системы TinEye.
TinEye - поисковая система, специализирующаяся на поиске изображений в Интернете. Конечно это не поисковая система Яндекс и Google. сервис TinEye специализирован только на поиске изображений. Одна из главных функций - это поиск изображений в Интернете по образцу, который дает пользователь. То есть TinEye ищет ваше изображение схожее или вообще копию в сети Интернете. Что то вроде проверка уникальности изображения. Аналог проверка уникальности текста в Интернете. Если сервис нашел копию вашей картинки в сети, то он выдает информацию: ссылку на это изображение (сайт), модификации картинки, может выдать в различных форматах.
TinEye полезна для веб-мастеров. которые хотят чтобы на их сайтах были уникальные изображения. И веб-мастер может проверить изображение на уникальность перед размещением его в сети.
Поиск изображения по образцуДля того чтобы начать поиск изображения по образцу, нужно на сайте TinEye в строке Upload your image нажать на кнопку Обзор и загрузить образец изображения, после начнется процесс поиска. Также можно поиск осуществить, указав ссылку на образец вашего изображения в строку Enter image address и нажав на кнопку Search .

Для подобных операций есть плагины для Firefox, Chrome, Safari, Internet Explorer и Opera, которые реально облегчат вам поиск изображения по образцу.
Ну есть еще не последняя бесплатная функция поисковой системы TinEye.
Поиск изображения по цветовой схемеСервис TinEye может осуществлять поиск изображения по цветовой схеме. Эта функция мне понравилась больше всего, я остался под впечатлениями. То есть тут можно искать изображения задавая цветовую схему. Добавляя по одному цвету, с каждым шагом появляются на странице TinEye картинки, где присутствуют именно указанные вами цвета. Очень полезная функция. Тут лучше убедится самим и пройти в специальный раздел TinEye. Как я понял поиск изображений осуществляется по сервису Flickr, база картинок, которая внушает - 10 миллионов.

Далее чтобы увеличить щелкам мушкой по понравившейся картинке и скачиваем на свой компьютер. Ничего подобного пока не встречал в сети Интернет. Советую воспользоваться и пополнить копилку онлайн инструментов.
А вот небольшой видеоролик про TinEye.
Когда вся музыкальная библиотека заслушана уже до уровня отторжения, а сетевые радиостанции не в состоянии удовлетворить ваш тонкий вкус, значит самое время отправиться на поиски новых звезд во всемирную сеть. В этом нам помогут онлайновые музыкальные сервисы, которые на основе наших музыкальных предпочтений помогут познакомиться с творчеством артистов, играющих похожую музыку.
 ©photo
©photo
Отличный и очень простой сервис. Вводим в строке поиска имя любимого музыканта и получаем отправную точку на карте для нашего музыкального путешествия. Щелкаем по этой точке и в появившемся меню выбираем команду Expand. после чего появляется список связанных исполнителей. Для некоторых исполнителей доступна информация о выпущенных альбомах, ссылки на официальный сайт и так далее.
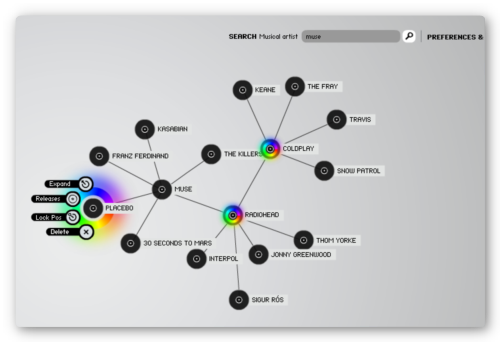
Добавим еще, что сделан сервис на флеше и выглядит просто замечательно: любой элемент можно таскать как угодно, а связи между ними мягко-упругие, впрочем посмотрите сами — интересно.
Этот сервис похож на предыдущий — точно так же вводим название любимого артиста и получаем список играющих в том же жанре. Однако здесь показываются сразу все известные сервису артисты, а о степени похожести можно судить по близости к образцу. Такая себе звездная космическая система получается.

Создатели Music Roamer явно вдохновлялись примером TuneGlue. Но внесли в свой продукт некоторое количество усовершенствований. Все артисты представлены небольшими фото, а сверху имеется панель настроек, с помощью которой можно настроить вид и поведение сервиса.
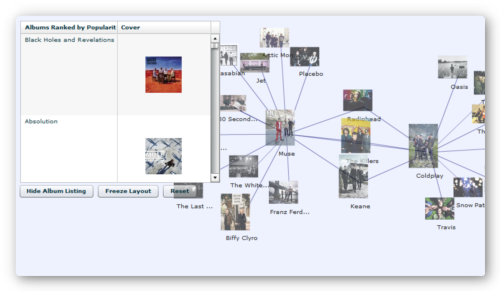
Bloson — это крупная социальная музыкальная сеть, которая содержит огромную музыкальную базу. Кстати, загляните в сведения о разработчиках (About Us) — вы с удивлением увидите, что индийские женщины могут не только хорошо танцевать, но и создавать отличные веб-сервисы. )
Но нас этот ресурс привлек, конечно, не этим, а возможностью отображения списка похожих артистов в ответ на введенное в строку поиска имя. Тут же можно почитать основные сведения и послушать-посмотреть музыкальные клипы.
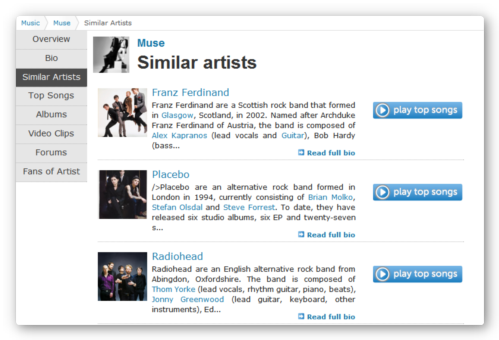
Конечно, мы не могли обойти стороной этой самый популярный и, возможно, самый насыщенный информацией музыкальный ресурс. Не смотря на то, что многие функции этого сервиса стали платными, кое-какую информацию можно здесь заполучить и без денег, в том числе список похожих исполнителей. С учетом того, что при составлении музыкальной базы здесь используются вкусы многочисленной армии пользователей, доверять рекомендациям Last.fm, несомненно, можно.

Удачных вам музыкальных открытий!
Всего голосов: 1
Месяц назад я обращался к теме сервисов, предлагающих поиск графической информации. Тогда рассматривались Picollator и Photodate. Жизнь не стоит на месте, графический интеллектуальный поиск - это тема, которая не разработана и на пол процента, ввиду того, что пока поисковые роботы не могут сравниться с человеком в образном мышлении. Кто первый научит своего робота искать правильно, т.е. так, как ожидается пользователями, тому будет счастье. Счастья хочется многим. Вот друзья поисковые роботы принели весть о том, что строится новый графический поисковик. По сети уже ходит его поисковый краулер TinEye /1.1, находящийся в состоянии тестирования. Разработчик - The Visual Search Company.
Судя по информации, представленной на их веб-сайте. компания это серьёзная. В клиентах есть Digg, использующий фирменную систему идентификации образов, использующуюся для предотващения дублирования загрузки картинок; Adobe, использующий систему Idee Piximilar для графического поиска в Adobe Photoshop Elements 6, а так же Агентство Франс-Пресс, использующее систему отслеживания публикации фотографий Idee PixID. Сервис Idee PixID. разрабатывающийся для мониторинга графической информации, позволяет, например, отследить, из каких оригинальных фотографий был составлен коллаж, что будет полезно авторам и фотоагентствам. На сайте можно посмотреть видео демонстрацию и примеры работы сервиса.
Сервисом Idee Piximilar можно даже попробовать воспользоваться на сайте labs.ideeinc.com. Доступно 3 вида поиска картинок: по основному цвету, по комбинации метки (tag) и графического образа, и, наконец, по загруженной картинке. Система работает достаточно стабильно. Так, на загруженную фотографию чайки она выдала 2 чайки, пару вальдшнепов, 4 удода, 2-х пеликанов, 1 самолёт, 3 стрекозы, 1 козла, 1 белого мишку и купающихся людей, а также 1 горящую спичку. Но лучше 1 раз увидеть:
Как видим, основным критерием здесь служит цветовая гамма картинки, вспомогательным - форма. Выдача преимущественно птиц по запросу чайки - это уже немалое достижение, поисковые роботы умнеют на глазах, но образное правополушарное мышление всё-таки крайне тяжело поддаётся формализации в машинный код.
Оно и понятно. Среди программистов преобладают люди логического склада :)
31 января 2011 17:15
 Чтобы найти в Интернете текст, достаточно воспользоваться любимым поисковиком. Но как отыскать фотографии, на которых запечатлено определенное лицо?
Чтобы найти в Интернете текст, достаточно воспользоваться любимым поисковиком. Но как отыскать фотографии, на которых запечатлено определенное лицо?
В этом Вам помогут специальные сервисы, о которых мы и расскажем в этой статье.
Главная проблема при работе с мультимедийной информацией (видео, аудио, картинки) состоит в сложности определения того, что именно содержат в себе такие файлы.
В любом случае видеоролики, аудио-треки и изображения, размещенные в Сети, описываются с помощью текста. Соответственно, поисковая система, которая ищет, например, картинку, анализирует комментарий к ней, чтобы определить изображенный на ней предмет.
Таким текстовым дополнением является, например, содержание тега «alt» с коротким названием картинки.
Для музыкальных и видеофайлов также используются теги. Однако текстовое описание мультимедийных файлов может не соответствовать их сути.
Например, в теге «alt» для репродукции картины Леонардо да Винчи «Мадонна Литта» можно написать «портрет Мадонны» — и тогда ошибки не избежать.
Сходство картинок используется в разных сферах нашей жизни.
Например, такой метод не первый год применяется в криминалистике — это поиск по фотороботу.
В реализации подобной возможности заинтересованы и фотографы, которые хотели бы знать, куда
именно по Сети разошлись их творения.
Кроме того, при поиске похожих картинок можно найти изображения с тем же содержимым, но лучшего качества.
Существующие онлайновые сервисы для розыска «фотодвойников» можно разделить на две группы — для поиска по готовому образцу и запросу.
В первом случае система находит графические файлы по заданному образцу. Во втором — пользователь составляет запрос и получает перечень картинок, причем для одной из них может быть предоставлен дополнительный список похожих вариантов.
Сервисы поиска по образцу
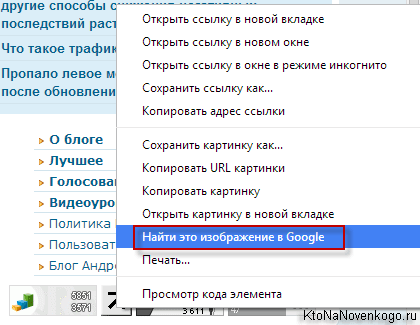
Эта поисковая система умеет находить картинки и фотографии, похожие на заданную. Система создавалась для поиска незаконных копий графических изображений и помогала обладателям авторских прав обнаружить плагиаторов. Сервис умеет работать с файлами в форматах JPG, PNG и GIF, размер которых не превышает 1 Мбайт. При этом сторона картинки не должна быть меньше 100 точек. Оригинальное фото следует загрузить на ресурс, после чего запустить поиск похожих картинок с помощью TinEye. Кроме того, можно искать картинки, похожие на уже размещенное в Интернете изображение. Для этого нужно указать его точный адрес. В результате система представит список найденных фотографий, где для каждой будет указано название сайта, на котором она размещена, имя, адрес и размер в пикселях и килобайтах.
Этот сервис умеет искать по собственной базе фотографий, а также снимкам, размещенным на сайтах знакомств. Для работы с сервисом пользователю необходимо закачать на сайт фотографию-эталон, выбрать способ сравнения и запустить поиск. В данный момент для поиска и сравнения можно выбрать фотографии мужчин, девушек, авторские работы и портфолио. Первые два варианта означают, что поиск будет проведен на сайтах знакомств, после чего отобразятся максимально похожие фото. По сравнению с другими аналогичными сервисами Photodate работает гораздо медленнее. Специальная шкала в верхней части сайта показывает количество обработанных фотографий. При поиске по портфолио система представляет фотографии из баз данных моделей. В случае с авторскими работами система использует фотобанки Рунета, в том числе и саму базу данных сайта Photodate.

Англоязычный сервис, работает на основе предложенного образца картинки либо уже имеющегося в Интернете изображения. Вместе с тем GazoPa — единственный ресурс, который позволяет указать дополнительные параметры поиска — например, когда нужна точность в цветовой гамме и требуется найти фото с похожими лицами. Здесь также можно установить ограничения на размер найденных файлов и задать поиск только монохромных картинок. Изображения в списке найденных вариантов оценены по уровню точности — он отображается в виде круговой диаграммы рядом с каждым фото. Чем больше голубого цвета, тем точнее картинка соответствует запросу. Кроме того, для фото с изображениями людей сервис позволяет осуществлять поиск лиц. В результате будут найдены фотографии персоналий, лица которых представлены на исходном групповом фото.
Поиск по текстовому запросу
При поиске изображений с помощью соответствующего раздела «Яндекса» можно получить список картинок, похожих на выбранную. Найденные дубликаты не отображаются в результатах поиска: наличие копий можно увидеть на странице предварительного просмотра повторяющейся картинки. Чтобы просмотреть список копий, нужно выбрать изображение в списке найденных. Рядом с ним будет размещен перечень «Копии картинки», в котором будут указаны ссылки на сайты, содержащие дубликаты, а также размеры найденных копий. При этом проводится поиск не только абсолютно схожих изображений, но и картинок, измененных различными способами. «Яндекс» утверждает, что может найти картинки после добавления надписей, изменения размера и даже степени сжатия.
Google Similar Images (www.similar-images.googlelabs.com)
 Google Similar Images — это экспериментальный сервис от Google Labs, который позволяет находить изображения, похожие на выбранное.
Google Similar Images — это экспериментальный сервис от Google Labs, который позволяет находить изображения, похожие на выбранное.
Вначале необходимо задать запрос, и если сервис готов предоставить результат, то ниже эталона будет размещена ссылка «Similar images» — она позволяет перейти на страницу с аналогичными по содержанию картинками.
Этот сервис работает не со всеми запросами, иногда это зависит от языка, на котором был сделан запрос.
 Это совсем новая поисковая система с красивым интерфейсом. Она тоже умеет находить похожие картинки.
Это совсем новая поисковая система с красивым интерфейсом. Она тоже умеет находить похожие картинки.
При поиске графических файлов рядом с каждым найденным вариантом появляется ссылка «Show similar images», которая ведет к перечню картинок, похожих на выделенную.
Важно отметить, что в данном сервисе просмотреть похожие картинки можно как при англоязычном, так и русскоязычном запросах.
Но главный ориентир здесь — текст.
 Поиск похожих изображений на основе запроса предлагает сервис Tiltomo.
Поиск похожих изображений на основе запроса предлагает сервис Tiltomo.
Базой поиска для него является фотохостинг Flickr. Задав запрос и получив результат — список найденных картинок, можно просмотреть перечень аналогичных вариантов по теме либо цвету (текстуре).
Если поиск тематически похожих картинок работает более-менее корректно, то, ориентируясь на цвет, вы, скорее всего, получите неверные результаты.
(По материалам журнала ?CHIP?)
Функции позволяют выбирать объекты, подобные объектам-образчикам как из всех объектов в чертеже, так и из определенного набора
![]()
![]()
При загрузке AutoCad. функция Выбор по образцу автоматически встраивается в контекстное меню:

Выбор по образцу (_MpSelSim)
Выберите объекты-образцы или [НАстройка]:
Следует выбрать один или несколько объектов, которые будут являться объектами-образчиками для поиска подобных. Поиск будет произведен по всем объектам в чертеже.
Открывает окно настройки функции (см.ниже)
Выбор по образцу из выбранного (_MpSelSimSel)
Выберите объекты-образцы или [НАстройка]:
Следует выбрать один или несколько объектов, которые будут являться объектами-образчиками для поиска подобных.
Выберите объекты в которых искать аналоги:
Следует выбрать объекты в которых будет произведен поиск подобных объектов
Открывает окно настройки функции:


Сохранить - Закрытие окна с сохранением параметров
Закрыть - Закрытие окна без сохранения параметров