








 Рейтинг: 4.1/5.0 (1839 проголосовавших)
Рейтинг: 4.1/5.0 (1839 проголосовавших)Категория: Инструкции
Приветствую сударей и сударынь!
Данная статья не связана с темой регистрации. Она не описывает работу отдельных ИФНС и не приводит образцы передаточного акта или протокола собрания. Эта статья напрямую посвящена двум-трём полезным советам, которые могут пригодиться в повседневном офисном делопроизводстве. Я знаю, что эти советы просты и широко известны – но, как оказывается, далеко не всем.
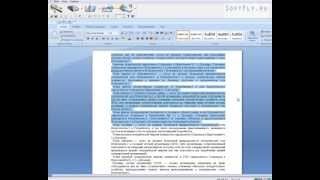
Как мы поступаем, когда нам нужно отсканированное изображение документа? Правильно. Распечатываем его и затем кладём под крышку сканера. Но есть способ проще. В этой инструкции я расскажу, как получить качественные изображения документов Word и Excel без предварительной распечатки и сканирования.
Такие изображения могут полностью заменить привычные «сканы», которые при обработке страниц сканером получаются далеко не всегда нужного качества и «красивости». Кому-то нужно распечатать «скан» либо отправить по почте, кому-то – разместить его на сайте, а то и загрузить в смартфон, и т.д. Для всех этих целей вполне подойдут картинки, полученные напрямую из документа. Качество картинок при этом может быть сравнимо с цифровой фотографией.
Необходимое условие – документ уже есть у вас в цифровом или текстовом формате – то есть он уже «набран».
Сама идея процесса проста. Превращаем документ Word / Excel в файл .pdf. Конвертируем файл .pdf в нужные вам картинки в формате .jpeg. Voila, вы получили отличное изображение без чёрных полос, получающихся иногда при работе со сканером.
А) Документ в .pdf
Для Word 2003. Устанавливаем программу doPDF. Она встраивает в систему виртуальный «принтер», при «печати» на котором Ваш документ без затруднений превращается в .pdf. То же самое проделываем для Excel. Альтернативы этой программе – BullzipPDFPrinter, PDF Creator. doPDF устанавливает в системе виртуальный «принтер», что позволяет «напечатать» .pdf-файл практически из любой программы, поддерживающей печать. В том числе и из абырвалг ППДГР .
Разобраться с настройками и возможностями программ несложно – просто устанавливаете, после чего при печати из документа Word выбираете в качестве принтера doPDF. Можно также запустить программу, просто кликнув по значку – она предложит вам выбрать файл и конвертировать его автоматически (правда, предложит по-английски, но тут затруднений быть не должно).
OpenOffice по умолчанию «умеет» конвертировать и текстовые, и файлы .doc и .xls в .pdf (в нём должна быть функция «Экспорт в PDF»). Те, у кого установлены различные FreeOffice, TextMaker, LibreOffice и прочее, могут попробовать проделать это в своей программе.
Для Word 2007. Скачиваем надстройку для сохранения документов сразу в формат .pdf. Запускаем файл-инсталлятор, который встраивает эту возможность прямо в Word 2007. При сохранении теперь вы можете выбрать формат .pdf.
Б) Конвертация .pdf в .jpg.
Проделать это можно как установленными на компьютере программами (тем же Fine Reader), так и при помощи многочисленных онлайн-«конвертеров», расположенных в Сети. Лично я предпочитаю давно известный мне pdf2jpg.net – простое и понятное меню процесса, видео с пояснением для тех, кто не разобрался, размер файла до 25 МБ, возможность выбрать качество конвертации и скачать архив со всеми изображениями одним файлом. Но если кому-то не понравилось, можете с лёгкостью найти конвертер, который объяснит вам всё на русском языке.
Если Интернет недоступен – придётся прибегнуть к помощи программ. Наиболее известную из них я уже назвал выше, но есть и альтернативы (PDF to JPEG Converter, или тот же PDFCreator, который позволяет сохранить файл .pdf в .jpg).
Также можно прибегнуть к хитрому способу – открываем pdf в любой программе, способной читать такие файлы, копируем изображение в буфер обмена, в графическом редакторе создаём новый пустой файл такого же размера и вставляем туда изображение. Здесь проблемка будет в том, что если в .pdf-файле много страниц, то гораздо проще реорганизовать… то есть, преобразовать его автоматически при помощи программы или интернет-конвертеров.
После того, как вы получили ваши документы в формате .jpg, можете приступать к дальнейшей работе с ними – отсылать по почте, открывать в графическом редакторе и т.д. Вот так можно «превратить» нужный документ в .jpg-изображение, совершенно не прибегая к распечатке и дальнейшему сканированию. При этом вы сохраняете бумагу, а возможно, и немного электроэнергии. Убей писателя – спаси дерево.









+ В список загрузок
А вот это совершенно бесплатная программа от российского разработчика Cognitive OpenOCR. Земляки позиционируют своё творение как интеллектуальную систему преобразования бумажных документов и графических файлов в редактируемый вид. В результате мы получим сохраненные структуру и гарнитуры шрифтов оригинала. Обрабатывать документы можно как в одиночном, так и в пакетном режиме.
Среди возможностей CuneiForm - сканирование текста и изображений; распознавание текста на 20 языках; работа с различными шрифтами (книжными, газетными, с пишущих машинок); распознавание таблиц и их содержимого (в том числе без сетки); «понимание» как чёрно-белых, так и цветных документов.
Программа отлично справляется даже с не очень качественными исходниками. Алгоритм оптического распознавания (именно так расшифровывается OCR), составляющий основу CuneiForm, преобразует в редактируемый вид и такие непростые оригиналы как текст с матричного принтера, плохие ксерокопии и факсы. А для улучшения качества распознания в CuneiForm предусмотрена опция словарной проверки. При этом пользователь может сам добавить новые слова, встречаемые в текстах, если таковые не найдутся в словаре. А для удобства обработки теста в электронном варианте к нашим услугам интегрированный текстовый редактор. Само меню представлено большими понятными кнопками (которых не так уж много), так что работать с ним сможет даже неискушенный юзер.
Все основные функции заложены в кнопку, на которой изображена «волшебная палочка», - это своеобразный мастер-проводник. Нажав на неё, вы пройдёте все этапы - от сканирования до редактирования и сохранения, лишь подтверждая операции. Единственный минус программы – это то, что она не поддерживает файлы формата PDF. В остальном, CuneiForm – превосходная программа для сканирования и распознавания текста. Скачать бесплатно её можно на любую версию Windows.
Здравствуйте! Помогите кто может, подскажите мне пожалуйста, как можно в Word 2007 быстро отредактировать отсканированный и распознаный текст. Есть ли для этого какая нибудь функция, или какие-то шаблоны или еще что-нибудь. необходимо это сделать быстро а просто вручную править весь текст нет времени да и занятие это не интересное. Вот в Word 2003 что-то вроде было для этого хотя я могу и ошибаться.
41792 / 34177 / 6122
10.08.2009, 10:58 Редактирование текста после сканирования
После регистрации реклама в сообщениях будет скрыта и будут доступны все возможности форума.
11.04.2011, 14:58 Редактирование текста после сканирования
Я когда-то работал наборщиком текста и сам для себя создал такую надстройку.
Пиши, договоримя: srgn.ru@mail.ru
12.04.2011, 14:33 Редактирование текста после сканирования
Есть ли для этого какая нибудь функция, или какие-то шаблоны или еще что-нибудь.
Чудес не бывает - нет такой функции. Можно использовать какую-нибудь функцию, но потом проверять текст надо всё-равно.
Попробуйте следующее (сам ни разу не использовал) - Формат - Автоформат .
Вообще, надо приучаться использовать Стили. Лучше использовать встроенные стили (а не создавать свои - чтобы было меньше хлама в документе), изменяя их под себя, а затем применять для изменения внешнего вида документа.
Стили менять надо так: Формат - Стили и форматирование - щ. правой кнопкой мыши по стилю - Изменить. Откроется диалоговое окно Изменение стиля. Чтобы стиль каждый раз не изменять, чтобы он был во всех новых документах, поставьте флажок Добавить в шаблон .
В сочетании со стилями надо использовать Темы (Формат - Тема. ). В данном случае изменяется одновременно вид нескольких стилей автоматически.
Проблема человека не в том, как сделать текст красивым, а в том, как довести его до ума после сканирования и распознвания. Это включает в себя множество действий, предшедствующих применению стилей. Например:
1. Нужно удалить все фигуры из текста, которые делает Fine Reader из-за грязных листочков или плохо распознаных таблиц;
2. Нужно стандартизировать параметры страницы
3. Нужно настроить абзацы: отступы до и после, выступы, запрет висячих строк и т.п.
4. Нужно проделать множесво операций по верстке самого текста. Главной задачей является сохранение исходного оформления (курсива, жирного выделения, выравнивания), но с применением стандартных (согласно учебным требованиям) размеров шрифта, начертания, масштаба знаков, трекинга и т.п.
5. Нужно поработать с таблицами: подогнать их по ширине экрана, определить заголовки, оформить согласно содержимому.
6. Нужно привести в порядок маркированные и нумерованные списки: программы для распознавания часто заменяют римские цифры на английскую букву "l" или на "!".
7. Есть ещё много-много мусора, которые ставяться FineReader-ом в конце предложений, хотя глазами видно, что там просто грязный листочек.
8. Нужно структурировать текст: избавиться от мягких переносов, разрывов предложений и слов (неправильно распознаются дефисы и тире).
Этот список можно ещё продолжить, но я хотел только показать сложность поставленной задачи и реальность её выполнения с помощью макросов.
Я СОГЛАСЕН С ТЕМ, ЧТО ОТРЕДАКТИРОВАННЫЙ ТАКИМ СПОСОБОМ ТЕКСТ ВСЁ РАВНО НУЖНО ПРОВЕРЯТЬ ГЛАЗАМИ, НО ДАЖЕ ЭТУ ПРОВЕРКУ МОЖНО ОБЛЕГЧИТЬ, ЕСЛИ НАПИСАТЬ МАКРОС ДЛЯ ПОДСВЕТКИ ПОДОЗРИТЕЛЬНЫХ МЕСТ, СПИСОК КОТОРЫХ МОЖНО ЗАРАНЕЕ ПРЕДВИДЕТЬ.
возможно, не по теме, не знаю где спросить, никто не знает как открыв файл с расширением djvu
часть выделить, копирнуть??
бывают файлы в формате pdf в которых нельзя выделить, копирнуть, что за ересь, как лечить??
Спасибо
djvu - выделить - правая кнопка, в контекстном меню выбрать "сохранить текст" - вставить в Word
pdf - нажать на панели инструментов "снимок" - выделить текст (скопируется при выделении в буфер) - вставить. Только вставится как рисунок, так лучше поступать с формулами. Предварительно в настройках надо активировать "делать снимки выделенного"
Проще всего распознать необходимое в FineReader.
Пробовала djvu переводить в pdf - получилось кривовато)))
Прошу прощения, выбрать "скопировать текст" (еще будет указано количество символов)
Коллеги, наверняка некоторые из Вас уже сталкивались с тем, что в MS Office 2010 нет возможности сканировать в многостраничный файл tiff. Я вот столкнулся, и оказалось что Microsoft отказались от инструмента Microsoft Office Document Scanning и Microsoft Office Document Imaging из 2003-го Офиса. Там было очень удобно сканировать в один файл.
Вот что говорит на счет этого мелкософт:
«In Office 2010, MODI is fully deprecated. This change also affects the setup tree, which no longer shows the MODI Help, OCR, or Indexing Service Filter nodes on the Tools menu. The Internet Fax feature in Office 2010 uses the Windows Fax printer driver to generate a fixed file format (TIF).»
Фактически они говорят, что «В 2010 офисе больше недоступен MODI, Интернет факс в 2010 офисе использует Windows Fax printer driver»
У нас же с вами остается немного вариантов для генерации многостраничных документов:
1) Использовать различное стороннее ПО
2) Установить из пакета 2003-его офиса тот самый Microsoft Office Document Imaging. это сделать просто.
![]()
![]()
![]()

Все, теперь у Вас установлен привычный инструмент для простого сканирования в многостраничный документ *.tiff
3) Этот вариант тоже имеет место в жизни для тех кто не хочет ни чего устанавливать. Здесь мы будем использовать простой макрос в Word 2010 для сканирования.
Скрипт сканирования MS Office 2010

Если Вы выбрали быстрый путь написания теоретической главы, о котором мы говорили в параграфе 2.1. вероятней всего Вам не обойтись без сканирования документов. В ином случае, этот пункт можете пропустить и начинать конспектировать материалы найденные в библиотеке .
Перед началом сканирования нужно определиться, что именно Вы хотите использовать при написании работы. А для этого нужно сначала просмотреть имеющуюся литературу и выделить карандашом нужные моменты.
Когда я впервые сканировал статью из журнала для своей первой курсовой, для меня это занятие было невообразимо сложным. В результате нескольких часов работы со сканером и FineReader’ом у меня на выходе вышла бредятина, не поддающаяся редактированию. В итоге пришлось все набирать руками. Чтобы у Вас не случилось подобного, рассмотрим подробнее все технические моменты сканирования.
Для сканирования нам, конечно же, потребуется сканер. Его не обязательно покупать. Можно, например, на время взять на время у товарища. Я пользуюсь сканером CanoScan Lide 60. Это хоть и не самая новая модель, но мне очень нравится этот компактный, быстрый и удобный в работе “девайс”. Если Вы взяли на время сканер, для того чтобы он работал нужно сначала установить программу-драйвер. Драйвера и руководство по установке всегда можно найти на установочном диске, который прилагается к устройству или скачать на сайте у производителя. После установки драйвера, подключите сканнер к компьютеру с помощью соединительного шнура. Теперь можно уже непосредственно приступить к сканированию.
Но сначала немного теории. Вы должны знать, что процесс сканирования состоит из двух этапов:
1. Непосредственно сканирование документа. На этом этапе сканнер как бы фотографирует поверхность сканируемого документа и сохраняет полученное изображение на компьютер в виде обычного файла .jpg .gif или в другом формате;
2. Распознавание документа. Это процесс преобразования текста из изображения сделанного сканером в обычный тест, который потом можно сохранить в Word и редактировать. Распознавание осуществляется без участия сканера, с помощью специальной программы (самая популярная Adobe FineReader). Таким образом, Вы можете сначала отсканировать несколько листов текста и сохранить их в виде изображения и только потом преобразовывать в текст.
Итак, начнем этап первый — сканирование :
— запускаем драйвер сканера: Пуск — Все программы — Canon — ScanGear (название драйвера я указываю для своего сканера). Появится окно драйвера:
— открываем крышку сканера и кладем книгу, журнал или их копию текстом вниз, как можно ровнее по отношению к краям рабочей поверхности сканера:

Здесь очень важно сделать так, чтобы крышка сканера как можно плотнее прижимала сканируемый документ, не допуская попадания внешнего освещения не рабочую поверхность сканера, которая соприкасается с документом;
— выполним необходимые установки в драйвере сканнера. Первым делом нужно установить разрешение, в котором будет отсканирован документ. Разрешение — это показатель, который определяет уровень детализации объекта при сканировании и определяется в точках на дюйм (dpi, или т/д). Чем больше разрешение, тем качественнее получается изображение. Но, при сканировании текстовых документов нет смысла устанавливать максимальное разрешение, поскольку толку от этого будет ноль. Кроме того, сканирование с большим разрешением занимает больше времени. Я рекомендую устанавливать разрешение в пределах 400-500 т/д (dpi). При такой настройке изображения получаются достаточно качественными для хорошего их распознания, а сам процесс сканирования не занимает много времени. Предлагаю посмотреть на скриншот установок моего принтера:

Для начала нужно перейти в «Расширенный режим». Источником всегда будет «Планшет» (планшетный сканер). Цветной режим лучше установить «Черно-белый». ведь для сканирования текста нам цвета не нужны, а это уменьшит размер изображений на выходе. Разрешение, как я уже сказал, следует установить 400 т/д. Выходной размер изображения — обязательно «А4». Теперь можно смело жать на кнопку «Сканировать». Мой сканер устроен таким образом, что сначала запоминает отсканированные изображения во внутренней памяти, и только при закрытии окна драйвера предлагает сохранить их на компьютер. Мне остается только указать место, куда будут сохранены результаты работы.
У вас должны получаться файлы такого типа:

При увеличении такого изображения должен быть отчетливо виден текст.
Второй этап — распознание полученных изображений и их преобразование в текст. Как я уже говорил, для этого понадобится специальная программа — FineReader. Скачайте программу по этой ссылке (32Мб). Пароль к архиву — diplomguide.ru. Предложенная мной версия не требует установки (portable). В папке с программой будет множество разных файлов, но Вам нужен только один — FineReader.exe. Двойной клик на этом файле запустит программу на Вашем компьютере.
Эта версия программы достаточно старая. Все скриншоты ниже я делал используя именно её. Если эта версия FineReader у вас не запускается — выберите более новую здесь .
Окно FineReader имеет следующий вид:

После установки языка, на котором напечатаны отсканированные Вами ранее документы, можно начинать распознание. Если в тексте присутствует сразу два языка (например, русский и английский) установку сделайте соответственно.
Чтобы начать распознание нажмите на стрелку справа от первой кнопки Сканировать — а затем — Открыть изображение:

Откроется окно выбора изображений. Откройте папку в которую Вы сохранили отсканированные изображения, нажмите CTRL + A (английское) на клавиатуре и нажмите на кнопку Открыть .

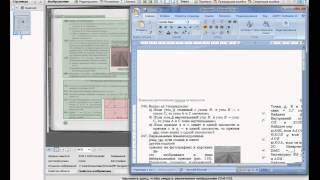
После этого слева в окне FineReader’а появятся эскизы добавленных файлов, по центру — на данный момент выделенный эскиз в увеличенном виде, снизу — еще большее увеличение, а справа результат распознания:

Для примера я взял всего два изображения. На скриншоте выше выделено первое из них, его сейчас и распознаем. Как видите, изображение отсканировано вертикально, чтобы распознать текст снимок нужно сначала развернуть на 90 градусов. Для этого воспользуемся кнопками  и
и  . Следующим шагом нужно указать программе, какую именно часть изображения нужно распознать, а также задать тип данных, которые должны получиться на выходе текст, таблица или изображение. Для этого существуют кнопки, соответственно:
. Следующим шагом нужно указать программе, какую именно часть изображения нужно распознать, а также задать тип данных, которые должны получиться на выходе текст, таблица или изображение. Для этого существуют кнопки, соответственно: 

 . Например, если нужно отметить текстовый блок, нажимаем левой кнопкой на , после этого нажимаем левой кнопкой мышки в левом верхнем углу текстового блока и, удерживая левую кнопку, перетягиваем в правый нижний угол. Для примера я полностью подготовил к распознанию одно изображение:
. Например, если нужно отметить текстовый блок, нажимаем левой кнопкой на , после этого нажимаем левой кнопкой мышки в левом верхнем углу текстового блока и, удерживая левую кнопку, перетягиваем в правый нижний угол. Для примера я полностью подготовил к распознанию одно изображение:

Как видите, все текстовые блоки в примере выше выделены зеленым, а рисунки — красным. Таблицы подготавливаются к распознанию аналогично. Для этого предназначена кнопка . Для того, чтобы перейти к следующему снимку, кликните левой кнопкой мыши на его эскизе слева. Таким образом подготавливаются к распознанию все полученные в результате сканирования изображения. После того, как подготовка изображений завершена, следует выделить их все. Для этого кликните левой кнопкой в пустом месте на панели эскизов (она называется Пакет ) и нажмите Ctrl+A (английское) на клавиатуре. Далее кликните на кнопку  и подождите пока FineReader преобразует изображения в текст. После этого можно сохранять полученный текст в Word с помощью кнопки
и подождите пока FineReader преобразует изображения в текст. После этого можно сохранять полученный текст в Word с помощью кнопки  , после нажатия на которую откроется окно Мастер сохранения результатов. В нем необходимо выбрать формат для сохранения — Microsoft Word, а также поставить отметку чтобы сохранились все страницы:
, после нажатия на которую откроется окно Мастер сохранения результатов. В нем необходимо выбрать формат для сохранения — Microsoft Word, а также поставить отметку чтобы сохранились все страницы:
После нажатия кнопки ОК программа создаст документ Word и вставит в него текст из распознанных страниц в том порядке, в котором они находятся на панели эскизов (Пакет). Полученный документ сразу же сохраните в папку в файловой структуре дипломной работы и можете приступать к редактированию. Как это делается, описано в моем бесплатном курсе .
И последний момент. Эсли Вы сканировали газету или журнал, текст там часто дается в виде колонок (как в рассматриваемом примере выше). Эти колонки в Ворде нужно преобразовать в одну. Выделите текст в виде колонок и выполните команду: Формат — Колонки — Одна — ОК. Только после этого можно ставить Книжную ориентацию в Параметрах страницы, отступы полей, шрифт и т.д.
Результатом сканирования является файл с изображением текста. Для создания редактируемого документа Word необходимо преобразование изображений в символы текста. В Solid Converter для этого предназначена функция OCR (оптическое распознавание текста).
Лучше всего распознавание происходит на документах, которые были распечатаны с помощью Word.Документ Word будет показан в Microsoft® Word с полным форматированием - колонками, рисунками и колонтитулами. Теперь можно переходить к редактированию документа.
Все виртуальные туры:
Здравствуйте. Сегодня я расскажу, как сканировать текст в документ Word. Зачем это нужно делать? Ответ очевиден, для дальнейшего редактирования текста. Ведь изображение не так просто будет отредактировать. Что лучше использовать, программы или онлайн сервис для перевода сканированного текста в документ Word? Об этом я расскажу ниже в статье.
Для того что бы максимально ускорить и упростить задачу. я искал сайты, на которых онлайн можно конвертировать сканированный документ в формат Word. Для этого мне пришлось сначала сканировать, а затем уже конвертировать. Сразу скажу, что многие сайты ограничивают количество переводов в Word, а что бы не ограничено конвертировать нужно заплатить. Мне удалось найти пару сайтов, которые не ограничено решают эту задачу, но делится не буду, так как конвертировать сканированный текст в Word онлайн оказалось пустой тратой времени. Процент распознания текста очень низкий. проще было бы перепечатать документ с нуля.
В таком случае, если онлайн инструменты на данный момент плохо переводят сканированный документ в Word. то как же сделать это максимально качественно? Читайте об этом дальше в статье, я приведу понятную инструкцию.
Погулив ещё несколько минут, нашел программу, называется ABBYY FineReader Professional. Наверняка Вы уже слышали про неё. Скачал её тут http://nnm-club.me/forum/viewtopic.php?t=851116. легко устанавливается и отлично работает.
ABBYY FineReader может перевести сканированные документы не только в Word, но и в PDF и многие другие текстовые и журнальные форматы.
Пользоваться ею очень просто. Устанавливаете и запускаете. На мониторе должны увидеть вот такое окно, как ниже не скриншоте.

Тут ничего сложного, интуитивно понятно, что нужно нажать в нашем случае на «Сканировать в Microsoft Word». Затем увидим окно настроек сканирования, в котором можно ничего не менять.

Поставим программе не простую задачу — сканировать и распознать страницу книги. Кладем книгу или любой другой документ на сканер и нажимаем сканировать. Программа начинает сканирование, а затем должна автоматически распознать документ. Если автоматического распознания не произошло. то нажмите правой кнопкой на сканированный документ и нажмите «Распознать». Ниже на скриншоте видно какой результат получился у меня.

Далее нажимаете на значок Word вверху и документ сохранится в текстовый формат документа Microsoft Word. Разумеется нужно учитывать, что распознанный текст нужно обязательно перечитывать, ведь в любом случае возможны ошибки.
Задавайте вопросы, пишите комментарии. Спасибо за внимание.
Почитайте ещё эти интересные статьи:В принципе, в пакете Майкрософт офис, по крайней мере, начиная с версии Xp, присутствует программа, при помощи которой, можно сканировать документы, и в том числе в Майкрософт ворд.
Таких программы даже две, Microsoft document scanning, и Microsoft document imading.
Но сканировать в этих программах не удобно, и долго.
Поэтому, мы обратимся к безусловному лидеру, в области сканирования и распознавания документов, программе, ABBYY FineReader.
Эта программа, имеет все необходимое для оптимальной и комфортной работы со сканерами и сканированным текстом.
И так первым делом, идем в настройки программы, и на вкладке сканирование открытие, устанавливаем интерфейс управления сканером, при помощи файнридера. Кроме того, можно установить такие параметры, как качество распознавания, цветное или черно белое изображение, и многие другие.
После этого в сканер, вставляем нужный документ, и в меню ABBYY FineReader, выбираем или сканировать, если это одна страница, или, сканировать несколько страниц, думаю все понятно.
После завершения сканирования, если в документах, присутствует текст, нажимаем распознать или распознать все.
Далее сохраняем документ, в формате ворд.








