




 Рейтинг: 4.6/5.0 (1881 проголосовавших)
Рейтинг: 4.6/5.0 (1881 проголосовавших)Категория: Инструкции
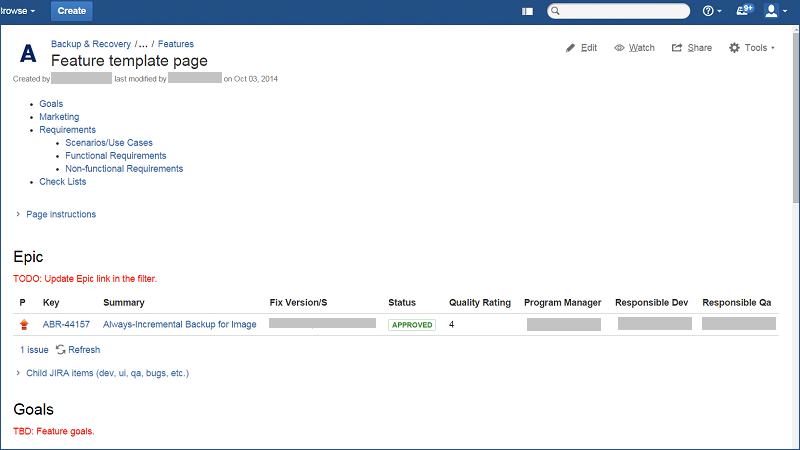
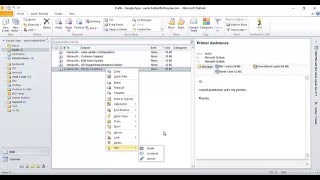
Кнопка Создать находится на всех страницах сайта http://support.latera.ru в правом верхнем углу.

Тип запроса может быть выбран любым (кроме Epic ) на усмотрение автора заявки. Тип Story подразумевает форму заявки, в которой не сформулирована конкретная задача, а лишь описана проблема и некие догадки по ее решению.

Как в теле заявки, так и в комментариях необходимо использовать теги разметки для более удобного представления информации. Наиболее часто используемые теги показаны на скриншоте. Подробное описание языка разметки можно найти, нажав на желтую кнопку с вопросительным знаком под формой для ввода текста.

Нажав на кнопку предварительного просмотра под формой для ввода текста, можно увидеть, как будет выглядеть текст заявки в готовом виде. Повторное нажатие возвращает текст в режим редактирования.

Заполните нужные поля после ввода заявки.

После того, как все данные будут введены, нажмите Создать .
Работа с заявкойИнформацию о том, как правильно создать заявку, можно найти в разделе Пошаговая инструкция по созданию заявки .
Для того, чтобы отредактировать уже существующую заявку, нужно нажать на кнопку Пр. в левом верхнем углу страницы.
Для удобного наблюдения за ходом выполнения работ существует функция Watch. Добавив себя в наблюдатели любой пользователь сможет получать уведомления на почту о ходе выполнения заявки. Если вы являетесь автором или исполнителем заявки, добавлять себя в наблюдатели не обязательно, уведомления на почту будут приходить в любом случае.
Сменить исполнителя можно только если заявку выполняют представители компании Заказчика. Исполнителей со стороны компании «Латера» нельзя изменить. Если вам необходимо назначить исполнителем заявки другого человека, сообщите об этом сотруднику компании «Латера», с которым вы работаете. Исполнителя имеет смысл менять, если работы по заявке перешли к другому человеку, даже если часть работ по заявке была выполнена первоначальным исполнителем.
Выполнив задачу, исполнитель задачи меняет ее статус на «Решено». Сделать это можно, нажав на кнопку Разрешение запроса .
Если по мнению Заказчика задача считается решенной, ее можно закрыть, нажав на кнопку Close Issue .












Программа представляет собой набор разделов, которые описывают подготовку специалиста по настройке и обслуживанию Atlassian Jira . Большинство крупных IT компаний уже оценили достоинства Jira Software и активно используют данное ПО в своих бизнес-процессах. Данный курс поможет системным администраторам, техническим специалистам, в чьи обязанности входит установка, настройка поддержка систем с Jira Software. разобраться с данной системой с нуля, сформировать понимание понятий, сущностей, которые есть в Jira и суметь настроить данный продукт практически любой сложности.
Кто может принять участие в обучении?студенты дневной или заочной формы обучения, предпочтительно, но не обязательно - технических специальностей, которые хотели бы овладеть навыками настройки и поддержки Jira
уже работающие специалисты, желающие узнать новые технологии, повысить свой уровень знаний и навыков и подняться по карьерной лестнице, получить более высокооплачиваемую работу. В данном случае представляют себя лично, а не компания инициировала обучение
сотрудники компаний, которые отправляют своих специалистов на обучение для повышения квалификации и достижения больших результатов в работе
Формат обучения:Комплекс теоретических и практических занятий. Теоретические занятия проходят в виде вебинаров 2 раза в неделю дистанционно по вечерам. Начало занятий, в зависимости от группы, в которую были распределены, на 19:00 или на 20:30. Одна лекция обычно длится 1-1,5 часа.
Практика проходит 1 раз в неделю, по выходным, чтобы можно было выделить достаточно много времени для отработки комплексных заданий.
Практические занятия для Киева доступны в очной форме - в классе с инструктором. Одно занятие длится обычно 3-4 часа.
Для остальных регионов обучение полностью дистанционное. Инструктор выдаёт задание для выполнения в специальной системе. При необходимости может быть инициирован skype-звонок или вэбинар для ответа на возникшие вопросы по практической работе. При этом студентам выдаются последовательные, понятные инструкции - что за чем выполнять. чтобы успешно выполнить практическую работу.
Информацию о времени проведения практики студентам будут передавать преподаватели. Группы выбираются небольшими, от 5 до 7 человек. чтобы всем было достаточно внимания.
Когда стартует следующая группа? Какое расписание? Где проходит обучение?Очное обучение - В Киеве - бульвар Ивана Лепсе, 4. Бизнес-центр. Как проехать - https://iteducenter.ua/contacts/nashi-kontakty.html
Для остальных регионов - полностью дистанционное обучение.
Период обучения:Курс "Администрирования Atlassian Jira" рассчитан на 3 недели. График нужно согласовывать отдельно.
Преподаватели:Наши преподаватели являются действующими сотрудниками IT компаний с большим опытом, сертифицированы во многих технических областях. Именно поэтому обучение у нас настолько эффективно!
Стоимость обучения:Демократичная цена 3 000 грн за весь курс "Администрирование Atlassian Jira", от А до Я.
Условия и оплата:С каждым студентом заключается договор на обучение. что гарантирует соблюдение наших обязательств. Реквизиты на оплату выдаются после подписания договора. Оплатить можно в любом банке, а также в популярной системе Приват24 либо сразу весь курс, либо частями.При оплате за весь курс действует скидка 10%.
Сокращения, принятые в программе курса:Теория, материал для изучения в базе знаний
5.3 Вручение сертификатов
По окончании курса студент будет знать и уметь :Основная изучаемая операционная система по нашей программе - Debian. Параллельно при изучении разделов курса, есть возможность сравнивать устанавливаемые и настраиваемые компоненты на Linux CentOS в нашей базе знаний. Таким образом, по окончанию данного курса, студент будет иметь знания и навыки по настройке Atlassian Jira сразу в 2х операционных системах - Debian и CentOS!
© 2016. NetForce Ukraine LLC. Все права защищены.
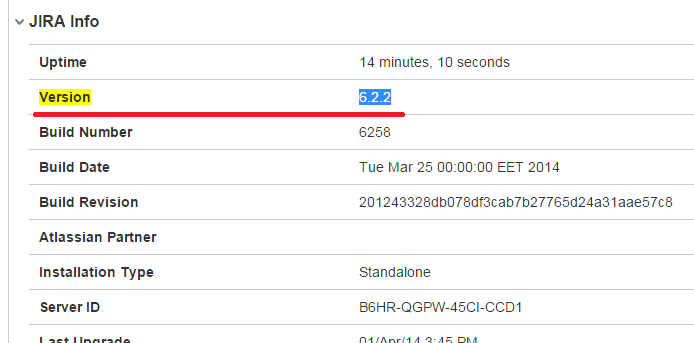
![]() Что бы найти текущую версию JIRA – переходим в ‘Administration’ > ‘System’ > ‘Troubleshooting and Support’ > ‘System Info’ :
Что бы найти текущую версию JIRA – переходим в ‘Administration’ > ‘System’ > ‘Troubleshooting and Support’ > ‘System Info’ :
Список последних версий можно найти тут>>>.
Там же находим и записываем catalina.base – это каталог Jira installation. в котором размещены все файлы JIRA. В данном случае это будет /home/jira/atlassian/jira .
Для JIRA имеется несколько типов обновлений, о которых можно почитать тут>>> .
В данном примере будет выполнено “быстрое” обновление.
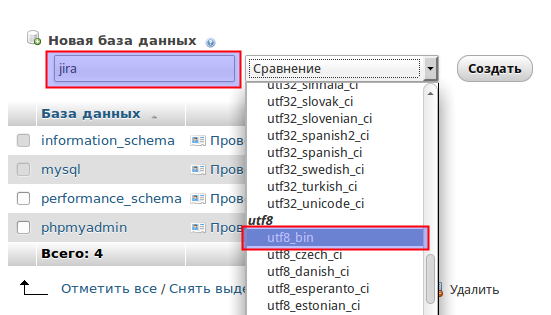
Находим базу данных JIRA :
Создаём резервную копию базы данных:
Во временную диреткорию загружаем новую версию со страницы загрузок JIRA (для загрузки версии для Linux – нажмите All JIRA download options ):
В случае ошибки:
ERROR: certificate common name “s1.wpc.edgecastcdn.net” doesn’t match requested host name “downloads.atlassian.com”.
Запускаем установку новой версии:
Далее выбираем Upgrade an existing JIRA installation :
Тут установщик JIRA сам нашёл Installation directory :
Делаем резевруню копию домашней директории JIRA :
И заходим в неё:
JIRA — это система, которая подходит для отслеживания ошибок и управления проектом в компании любого размера. Это инструмент для всех сотрудников в команде и руководителей проектов.
JIRA помогает команде обмениваться информацией и легко вовлекать разных сотрудников в проекты и задачи, отслеживать и фиксировать ошибки пользователей в работе с программными продуктами, обеспечивать соблюдение работы точно в срок и в рамках регламента рабочего процесса, проверять и планировать эффективность работников и назначать определённые задачи, работать вместе с коллегами с помощью инструментов совместного редактирования файлов, а также отслеживать прогресс и обновление каждой задачи команды.
Динамичные инструменты системы для управления проектами JIRA дают возможность руководителям обнаружить препятствия, которые не дают команде работать эффективнее, принимать целенаправленные действия по их устранению и определять области улучшения рабочего процесса.
Основные возможности JIRA:
Доступные языки: English
Безопасность и конфиденциальность![]() Доступ по протоколу HTTPS Данные между вами и сервисом передаются по шифрованному каналу (SSL/TLS), что исключает их перехват злоумышленниками.
Доступ по протоколу HTTPS Данные между вами и сервисом передаются по шифрованному каналу (SSL/TLS), что исключает их перехват злоумышленниками.
![]() Многофакторная авторизация Совместное использование нескольких факторов снижает риск утечки данных (помимо пароля, применяются карты, сканеры отпечатков пальцев и др.)
Многофакторная авторизация Совместное использование нескольких факторов снижает риск утечки данных (помимо пароля, применяются карты, сканеры отпечатков пальцев и др.)
![]() Резервное копирование в нескольких местах Резервное копирование данных в несколько независимых мест делает практически невозможным их потерю или повреждение.
Резервное копирование в нескольких местах Резервное копирование данных в несколько независимых мест делает практически невозможным их потерю или повреждение.
![]() Информация о запущенных программах
Информация о запущенных программах
Отличный дизайн, создаваемый по гайдлайнам, в итоге такие сервисы от Atlassian как JIRA, Bamboo, Confluence выглядит гармонично и ими приятно пользоваться.
Удобный интерфейс, рабочие столы, которые можно настроить под себя, возможность искать задачи по гибким фильтрам.
Не навязчивое логирование времени, удобные комментарии.
В работе заметил, что не хватает виджета календаря, в котором можно было бы планировать наперёд свои задачи и знать чем займёшься в тот или иной день, хотя может быть не разобрался до конца
Действительно JIRA (и весь комплекс сервисов) можно считать лидерами в области продукт менеджмента и багтрекинга, это удобный сервис, который поможет организовать команду разработчиков, тестировщиков и остальных сотрудников как крупных компаний, так и не совсем. Абсолютно точно рекомендую.
![]()
Пятница, 06 Ноября 2015 г. 15:30 (ссылка )
В предыдущей публикации я описывал список продуктов и их настройки, которые необходимы для работы нашей организации.
В этой статье я постараюсь описать как мы это всё используем в ежедневной работе всего коллектива разработки.
На протяжении 4х лет у нас выработался следующий формат команды разработки:
В итоге команда размером около 10-11 человек. Таких команд (ячеек) у нас несколько.
Работа в основном в стиле стартапа, когда нет конкретной и подробной постановки. Очень часто эксперименты вроде “а давайте попробуем так, посмотрим что получится” или “вы классно все сделали, но теперь надо все совсем по-другому”.
За эти годы концепцию нашей работы можно описать одной фразой — это “стремительная смена концепции”.
Понятное дело, что применить в таких условиях различные методологии никак не удавалось.
Начинал в этой системе я как программист, потом Team lead, ну а теперь PM (DM). Т.е. руковожу, полностью участвую в проектировании и иногда даже пописываю. Во времена моего программирования у меня был замечательный ПМ (выходец из тестировщиков), которая поддерживала все мои идеи по автоматизации workflow. Даже более того, концептуально этот процесс придуман ей, а я уже смог его технически реализовать и в некоторых местах усовершенствовать.
Перейдем к сути.Как мы работали ранее с использованием только Jira и SVN:
После сложного пути проб и ошибок, спустя 3 года мы пришли к следующему процессу.

Все задачи появляются у нас либо после совещания с высшим руководством, либо пожелания от заказчика, либо придумываем что-то сами (или находим баги).
В случаях, когда задача не односложная, собирается мини-совещание из ПМ, тимлида, QA-лида и аналитика. После обсуждения и придумывания, что и как будем разрабатывать, обычно сразу дробим это на логически завершенные небольшие задачки (не дольше работы 1го дня программиста) и грубо прикидываем сроки на реализацию (для планов для высшего руководства).
Аналитик садится и вдумчиво излагает постановку в Confluence. После этого данную постановку согласовывает с ПМ, а тот при необходимости с высшим руководством.
Затем на основании этой постановки создается задача в Jira.
Часто задачи сразу появляются в Jira минуя этап с Confluence.
Любая задача, которая появляется в Jira сразу попадает на шаг “Постановка задачи”. На данном этапе заполняются такие данные как:
На этапе постановки задача находится у ее автора и на нее больше никто не смотрит и о ней не знает.
Как только автор окончательно формулирует постановку задачи, он ее толкает на следующий (единственно возможный) шаг в workflow — ревизия постановки.
Ревизия постановкиПри переходе на этот шаг триггеры Jira автоматом меняют ответственного задачи на ПМ-а.
Этот шаг предназначен для того, чтобы ПМ перечитал описание задачи и убедился, что автор правильно понял постановку и корректно описал задание для программиста. Очень часто из-за недостаточного взаимопонимания задача делается и тестируется до самого конца и только уже при релизе видно, что сделали совсем не то, что изначально требовалось.
Так же на этом шаге ПМ принимает решение нужно ли реализовывать вообще данную задачу. Или нужно ли ее реализовывать именно в эту версию.
На этом этапе есть два варианта workflow: вернуть назад на постановку (доработку описания) или продвинуть дальше в работу.
Так же я часто на этом шаге назначаю ответственного тимлида для того чтобы он сам определил исполнителя
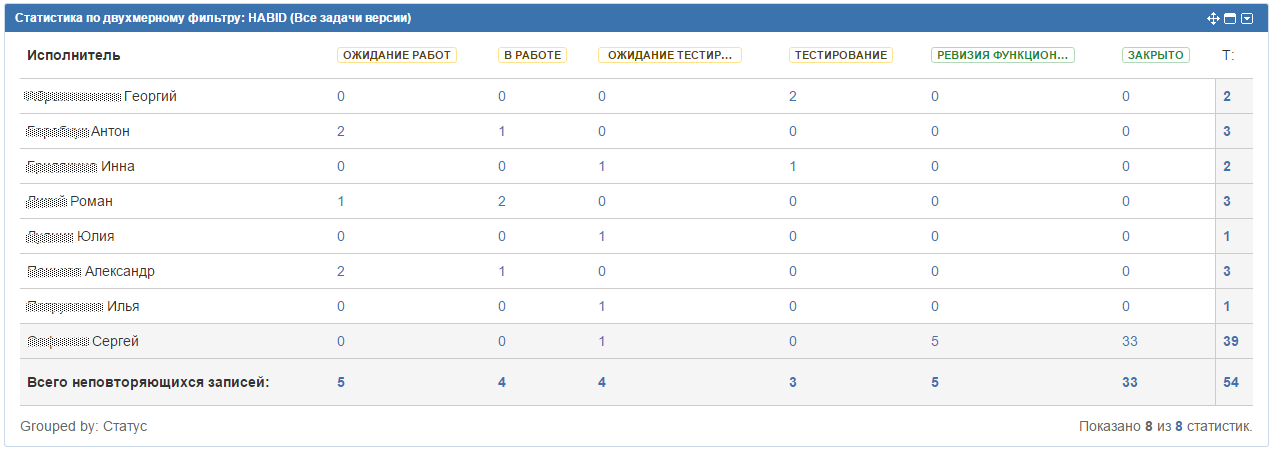
Ожидание работ
При выборе этого шага я настроил экран, в котором надо задавать исполнителя, поле “Программист” и планируемое время.
Этот шаг — пул задач программиста, который надо выполнить за версию в порядке, указанном в поле приоритет или в порядке любом удобном, если приоритет одинаковый.
Так уж получается, что во время работы над версией частенько этот список пополняется.
В работеНажимая на кнопку “В работу”, задача переходит в состояние “В работе” и благодаря плагину “Automated Log Work for JIRA” автоматически запускается счетчик логирования времени, который останавливается и сохраняет набежавшее значение при переводе задачи в другие статусы. На этом шаге программист может:
Чтобы работала связка FishEye+Crucible+Bitbucket+Jira, при комите программист обязательно в коменте должен указать номер задачи (PRJ-343).
У нас в команде договоренность, что мелкие правки типа подвинуть кнопку правее или раскрасить зелёный зеленее, можно сразу бросать на сборку. Иначе — ОБЯЗАТЕЛЬНО на ревизию кода.
И так, бросаем задачу на ревизию кода, и при этом ответственным назначаем тимлида.
Ревизия кодаНа этом шаге тимлид в специальной секции Development в Jira смотрит какой именно комит был сделан программистом и нажимает специальную кнопку “Code Review”.

После нажатия автоматически открывается Crucible и создается ревью на указанный комит (или несколько комитов).
Тимлид может видеть дерево файлов, которые правил программист ну и соответственно диференсы. Может оставить комментарий к любой строке кода или общий к ревизии. Crucible позволяет даже указать степень критичности проезда программиста.
После мук изучения чужого гуанокода, тимлид либо проталкивает задачу на шаг сборки, либо возвращает программисту в ожидание работ.
Программист в этом случае в секции Development видит Code Review и его статус. При переходе на этот Code Review опять же открывается Crucible, где программист может наглядно увидеть, где именно он налажал.
При переводе на шаг “Ожидание сборки”, тимлид выбирает ответственным тестировщика, который указан в спец поле, либо если оно не заполнено, то QA-лида.
Ожидание сборкиТак как сервер тестирования у нас один общий, то сборка по расписанию не годится. Нельзя подменять сайт во время его тестирования.
Поэтому, обычно у нас тестировщики договариваются и, если никто не против, собирают себе свежую версию ресурса.
Делают они это с помощью Jenkins. В нем созданы по три сборки на каждый проект: сборка для тестов, сборка для разработки, сборка БД.
В сборке исходников настроен следующий алгоритм:
В сборках БД все тоже самое, только вместо шага 3 выполняется следующее с помощью ssh команд на сервере:
3.1. Отрубить все коннекты к БД.
3.3. Восстановить БД прошлой версии.
3.4. Прокрутить на ней все скрипты новой версии.
БД у нас собирают крайне редко, только когда тестировщик видит в измененных файлах sql скрипты.
Ожидание тестированияНа этом шаге могут быть задачи, которые уже были в тесте, а могут быть и в первый раз. Если задача уже в тесте была, то тимлид уже ответственным ставит именно того тестировщика, который вернул задачу в работу.
Иначе все задачи скапливаются у QA-лида. Он смотрит на пул задач и нагрузку каждого тестировщика, и определяет кому назначить задачу на тест. Более того, сразу же определяет и тестировщика для парного тестирования.
ТестированиеС данного шага, задачу можно перевести практически на любой шаг workflow. Тестировщик может:
Так же как и с шагом “В работе”, на этом шаге автоматически запускается счетчик времени, который логирует затраченное на работу время.
Ожидание парного тестированияЭтот шаг был придуман по нескольким причинам. Многие не понимали его целесообразности, но в итоге спустя какие-то время соглашались, что он необходим.
Суть его заключается в том, что есть основной тестировщик по задаче, который очень глубоко и усиленно ковыряет задачу со всевозможных аспектов и есть парный тестировщик, который поверхностно просматривает задачу только после полностью завершенных тестов первого. Это очень похоже на ревизию кода у программистов.
В итоге получаем то, что не только один тестировщик знает как устроена та или иная функциональность. Если задача футболялась 10 раз между программистом и тестировщиком, то свежий взгляд парного тестировщика может заметить что-то пропущенное. Ну и самое важное, то что каждый тестировщик работает по своему и привыкает использовать софт определенным образом (логинится не используя мышь, аплоадить файлы драг-н-дропом, вместо фильтров использовать сортировки, при вводе данных копипастить тексты и т.д.). Очень часто бывает, что одни и те же функции можно использовать по-разному, и парный тестировщик натыкается на ошибки, которые были проверены основным, но немного по-своему.
Парное тестированиеЕсли на этом шаге обычно уже можно считать, что задача почти закончена. И очень часто, когда поторапливают с выпуском версии, его можно пройти формально.
ReadMeПосле успешно проведенных тестирований уже окончательно определена функциональность и ее реализация. И вот теперь этой задачей занимается техпис. Обычно все задачи, кроме совсем незначительных или тех, которые сами сломали в процессе работы над версией, мы помечаем меткой “ReadMe”.
Парный тестировщик, если видит эту метку отправляет задачу на шаг “ReadMe” и назначает на техписа.
Техпис в специальном поле описывает очень кратко Release notes по этой задаче. Обычно это оповещение пользователя об изменении функциональности или исправлении ошибки, или о появлении новой функциональности и как ей пользоваться.
На этом же шаге техпис исправляет или дополняет справку ресурса в Confluence.
После проделанной работы, задача отправляется на финальный шаг “Ревизия функциональности”.
Ревизия функциональностиПри переходе задачи на этот шаг, триггеры Jira автоматом назначают ответственным ПМ-а.
На этом шаге ПМ проверяет работу всей команды в целом. Было ли реализовано то что хотели, именно так как хотели, нормальное ли описание в ReadMe и т.д.
Бывает, что на этом шаге оказывалось, что программист с тестировщиком что-то между собой порешали и отрезали “ненужную функциональность” или изменили ее потому что посчитали так лучше, и именно эта функциональность требовалась высшим руководством и именно в таком виде. Тогда задача опять идет на “Ожидание работ”.
Ценность данного шага заключается в том, что хороший ПМ или ДМ после выпуска и звонка заказчика с фразой “что вы наделали?”, должен знать как именно реализовали задачу, как назвали кнопки, тексты сообщений, нюансы алгоритмов и смело ответить “сам дурак”. А не мяться и гадать, а как же они сделали ту форму и чего в ней кнопка задизейблена…
ЗакрытоНу тут все и так понятно. Задача закрывается после удачно прошедшей ревизии функциональности.
Или задача в любой момент может оказаться никому не нужной, потому переход на этот шаг возможен с любого другого шага.
Рабочий столДля удобства в Jira были разработаны рабочие столы для каждого проекта с четырьмя гаджетами:

Еще с помощью GreenHopper я настроил такую доску:

Очень удобна для обзора всего процесса целиком.
Выпуск версииПри выпуске версии, мы выгружаем из Jira все задачи версии в виде двух колонок: компонент и поле ReadMe. Вот и получается у нас ReadMe сгруппированное по разделам.
С помощью “Scroll HTML Exporter” мы экспортируем страницу хелпа в Confluence и все ее дочерние страницы в набор html файлов, которые внутри выглядят так же красиво как в Confluence и ссылаются друг на друга.
ИтогиВот по такому workflow мы уже работаем несколько лет, иногда его дорабатывая и дотачивая.
Но в целом он очень удобен.
Для ПМ тем, что в любой момент времени видно кто именно и на каком шаге держит задачу.
Для разработчиков удобно видеть только свой объем работ.
Ну и конечно же автоматизация на всех шагах. Т.е. нет такого человека без которого рабочий процесс может остановиться.
[Из песочницы] Автоматизация workflow небольшой команды разработки (Часть 1)Пятница, 06 Ноября 2015 г. 13:01 (ссылка )
Практически во всех местах моей работы программистом для разработки использовали всего два продукта: багтрекинг и систему контроля версий. Чаще всего это были Atlassian Jira и SVN. В принципе, наличие этих двух систем здорово упорядочивает общение всех участников процесса разработки и положительно влияет на качество работы отдела и продукта.
Года 4 назад я морально, а затем и фактически дорос до уровня тимлида. Взгляды стали шире и выше текущих процессов. В голову стали приходить разные мысли о мотивации, оптимизации, автоматизации и прочих -циях. В этой статье я хотел бы поделиться опытом из разряда технических компетенций тимлида: как автоматизировать ежедневные процессы (например, автоматическая сборка продукта, выкладывание, документирование, управление правами т.д. и т.п.).
После третьей страницы текста моей статьи, я решил разделить ее на 2 блока:
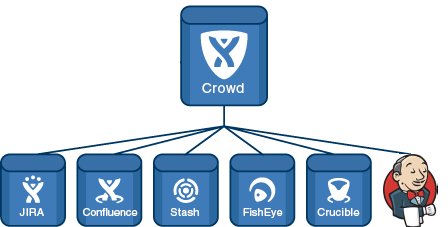
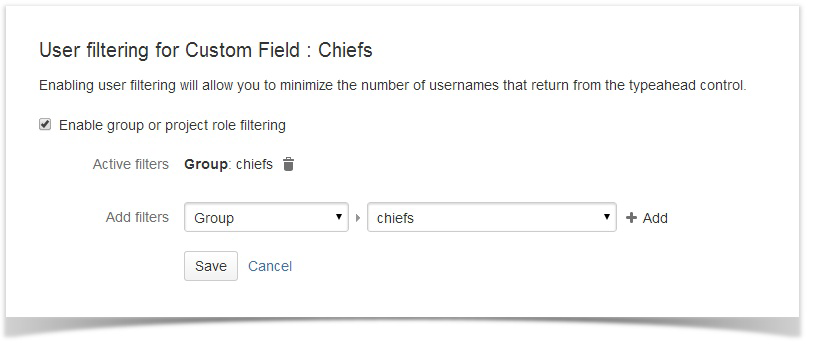
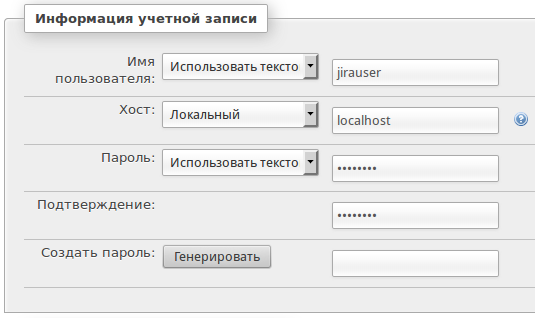
Первым был Crowd — менеджер учетных записей. Я скрестил и синхронизировал его с Jira. Crowd втянул в себя все группы и всех пользователей Jira. В Jira работу с директорией Crowd я сделал read/write (поскольку нового пользователя добавлять через Jira удобнее чем через Crowd).
В Jira всех пользователей разбил на группы:
Обязательная группа для всех пользователей.Только разработчики этого проекта.
В каждом проекте Jira позволяет настроить 3 роли. В роль USERS я занёс группу project1-users, в роль DEVELOPERS занёс project1-developers, а в роль ADMINISTRATORS занёс PM (менеджера проекта).
Если вкратце, то юзеры в группе могут только создавать задачки и наблюдать за ними, девелоперы могут их редактировать и решать, а админы управляют версиями, компонентами, могут удалять или редактировать чужие комментарии или задачи.
ConfluenceЯ считаю этот продукт самым удачным среди всевозможных баз знаний. После прочтения большого количества статей и сравнения разных систем, я пришел к выводу, что Confluence среди них бесспорный лидер.
В нем я создал разные Пространства:
Общие сведения по работе предприятия (параметры FTP хранилища, Wi-Fi, правила оплаты овертаймов, учета отпускных, контакты сотрудников, обсуждения корпоративов, инструкция по подключению принтера и т.д. и т.п.)Всё то, что в предыдущей группе только касаемо данного проекта (нюансы костылей, полезные sql запросы), юзерстори, постановки, входящие данные (дизайны, логотипы, иконки, параметры доступов), исходящие данные (ридми, инструкции, релиз ноутс), планы тестирования, описание механизмов, модулей, и т.д. и т.п.
Самое главное и приятное, что Confluence любую свою статью умеет красиво экспортировать автономные HTML страницы.
Весь хелп у нас хранится в Confluence в виде иерархической структуры статей. В конце версии одним кликом получается пачка HTML файлов, которые ссылаются друг на друга. Все это удовольствие мы просто копируем в проект и выпускаем. И потому справка у нас постраничная (а не все в одном огромном файле), легко поддерживаемая и всегда онлайн доступна для всей команды (а не где-то у кого-то в какой-то папке).
Каждый проект Jira и пространство Confluence связаны. В статье с постановкой есть ссылка на задачу и наоборот.
BitbucketДля хранения исходников мы исторически использовали SVN. Влияние новых технологий не прошло мимо, и конечно же выбор пал на git (бест практик как никак).
Поскольку я программист, а не сисадмин, установку чистого гита я не осилил. Потому взял готовый пакет GitBlit… но вскоре в нём разочаровался. В результате все перевёл на GitLab.
Год работы и 12 одновременно действующих проектов дали о себе знать. Сервер стал прогибаться под тяжестью руби. К тому же сказалась очень слабая совместимость с Atlassian продуктами.
В то время я заметил Stash. В чистом виде под линукс я, к сожалению, его не нашёл, за то поставил его в составе Bitbucket. И понеслась!
Создал проекты и по репозиторию в каждом. Дал полные права каждому ПМ-у на свой проект (теперь он сам может создавать репозитории в своём проекте сколько хочет). В репозитории на мастер ветку выдал права только лиду и по умолчанию выставил ветку dev.
Скрестил Bitbucket с Jira и теперь в каждой задаче есть список всех комитов по задаче. А из комитов можно переходить на задачки.
Fisheye and CrucibleГде-то я читал, что Crucible можно встроить в Stash. Но поизучав детально уже настроенный Bitbucket, я ничего подобного не нашёл. А так как CodeReview — обязательный этап в нашем Workflow, то пришлось ставить и Fisheye. Реально очень удобная штука, но имея Bitbucket, можно было обойтись и без неё.
Когда у нас стоял GitLab, добавлять репозитории в Fisheye было реально морочно… Куча настроек, генерация ключей, левые юзеры… С Bitbucket все пошло как по маслу. Скрестил Fisheye и Bitbucket и в Fisheye появился список всех репозиториев с кнопочкой “add”.
Создал проекты, указал в них группы разработки те, что в Jira для этих проектов, указал репозиторий и скрестил каждый со своим проектом в Jira. А в Jira наоборот указал в каждом проекте линки на Fisheye и Crucible и путь к репозиторию.
Теперь в каждой задаче есть комиты по задаче не только из Bitbucket, но и из Fisheye. Безтолково, конечно….но ничего страшного. Зато в каждой задаче теперь можно сразу увидеть Review и его статус!
JenkinsВот вроде бы и все, но нет! Надо же это все хозяйство как то автоматизированно собирать. Очень долго хотел прикрутить Bamboo, но он выглядит ущербно по сравнению с Jenkins. В Jenkins мне удавалось настроить автосборку всего еще и с перламутровыми пуговицами. В Bamboo все не так. Сообщество слабое, плагинов мало, можно рулить только выполнением консольных команд. Перечислять недостатки не буду. В начале настраивал под сборку Delphi-проектов, но потом перешли на веб и сборки стали простыми — вытащил, залил на ftp, отметил в Jira и письма разослал. Подумаю, может и на Bamboo перейдем.
Значит скрещивать Jenkins ни с кем не стал. Вроде как нужды нет. Никому не интересно в задаче сколько раз она собиралась. Единственное что — это в самом Jenkins поставил Jira plugin, чтобы при сборке задачи автоматически перемещались на другой шаг WorkFlow.
И важно все вышеперечисленные продукты обязательно настроить на Crowd. Единые учетки во всех этих системах — это реально удобно. При найме нового члена команды, достаточно его просто занести в Jira и указать его группу-проект и он имеет доступ ко всему. Точно так же и при увольнении. В одном месте выключил и доступа нет никуда.
Уголок сисадминаСервер у нас стоит Xeon X3430 4CPUs x 2,4 Ghz, 8 GB, 1TB
Вначале, я поднял Windows Server и на нем все эти продукты сразу + Ubuntu для GitLab. Сервер не осилил, раз в два часа просто зависал на 10 мин.
После этого принял решение разделить по разным виртуалкам. Вот что получилось:
Gateway — для выхода в Интернет (4 ядра, 4ГБ ОЗУ) — эта виртуалка мне уже досталась от админа, который этот сервер первоначально настраивал.
Jira — 2 ядра, 2ГБ ОЗУ
Confluence — 2 ядра, 2ГБ ОЗУ
Bitbucket&Jenkins — 2 ядра, 2ГБ ОЗУ
Crowd&FishEye&FTP — 2 ядра, 2ГБ ОЗУ
Все виртуалки на Linux Debian 8.2
Теперь все эти продукты летают, и зависаний, как раньше, нет.
На виртуалке Gateway пробросил два порта чтобы снаружи были доступны Jira и Confluence. Размышляю над тем, чтобы еще пробросить порт для доступа к Git. Но чтобы было более секурно, только ssh доступ.
ИтогиВот и готовы сервера и все необходимые продукты для полной автоматизации workflow разработки. В следующей части я постараюсь подробно описать как взаимодействуют эти все продукты ежедневно в процессе разработки.
P.S. Я посчитал ненужным описывать подробную настройку каждого продукта Atlassian из-за того, что статья стала бы очень длинной и сложной. Если у уважаемого сообщества будет желание ознакомиться с моим опытом, я с удовольствием опишу и эти нюансы настроек.

20 октября в офисе компании Mail.Ru Group во второй раз соберутся участники сообщества Moscow Atlassian. Единомышленники поделятся практическим опытом и обсудят тонкости использования продуктов линейки Atlassian. В программе, как обычно, несколько докладов и общение гостей за чашкой кофе.
Несколько советов о том, как избежать серьезных ошибок при администрировании JIRA. Как предупредить снижение производительности с ростом системы и предотвратить длительные простои из-за собственной лени. Основано на реальных событиях.
Мы в компании активно переходим из трех различных трекинговых систем в JIRA, точнее уже находимся на финальной стадии. Всего сущностей для переноса — порядка 500 000. В докладе я расскажу, как это было. Сначала подход к миграции был через API, потом мы столкнулись с необходимостью переноса истории, дат, аттачей и т.п. а также слишком длительным временем миграции. Подход менялся, и в конце концов путем проб, ошибок и опытов со структурой БД был полностью переработан в сторону прямой миграции в БД. Общее время значительно уменьшилось, скорость стала более чем хорошей, чистота данных увеличилась.
JIRA — мощный инструмент в умелых руках. Однако часто случается так, что даже при наличии столь многофункционального оружия, мы не всегда знаем как им пользоваться в полную силу. Мой доклад расскажет о нюансах использвоания JIRA, удобных механиках нативного функционала JIRA и ряда плагинов к нему, которые позволяют выстроить процессы разработки и тестирования.
Чего не будет в этом докладе:
В компании Align Technology мы используем Bamboo более четырех лет. За это время удалось вырастить бамбук практически до максимального размера (по меркам bamboo, 80+ агентов). У нас есть множество разных технологий и требований, и мы учились на собственных ошибках. Доклад расскажет о проблемах большой фермы и их решении (или почему 100 агентов — это действительно максимум).
Начало в 19:00. Адрес: Ленинградский проспект 39, стр. 79 (м. «Аэропорт).
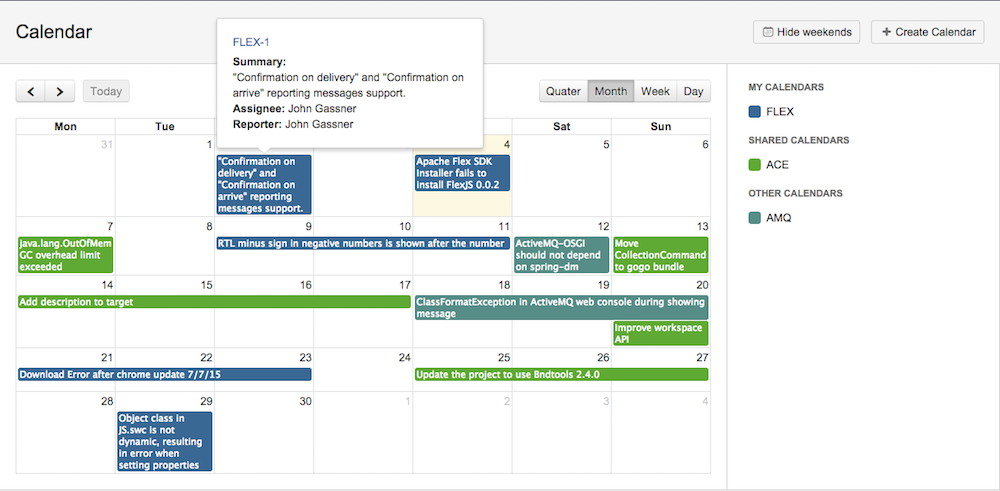
Здравствуйте, дорогие хабражители! Сегодня мы бы хотели рассказать о календаре, который используем в JIRA. Не так давно мы обновили его, а так как статьи о нем никогда и не было, то решили написать о нем в целом, а не только об изменениях. Подробности под катом.
Чего хотелось?Плюс хотелось бы добавлять новые возможности по мере необходимости, а все более или менее подходящие решения были с закрытым исходным кодом.
Что получили?На странице календаря вы увидите 2 блока, не считая header-а. В левом — события, в правом — сами календари. Календари разбиты на 3 группы: Мои календари, Расшаренные календари и Остальные. Последняя группа видна только администраторам JIRA. Первая группа говорит сама за себя, во вторую входят календари, расшаренные на вас, либо через группу, либо через проектную роль. В третьей группе администраторы видят все календари, не вошедшие в первые 2 группы. Администраторы вольны делать практически все со всеми календрарями: удалять, редактировать любое поле, изменять группы и проектные роли для шары.
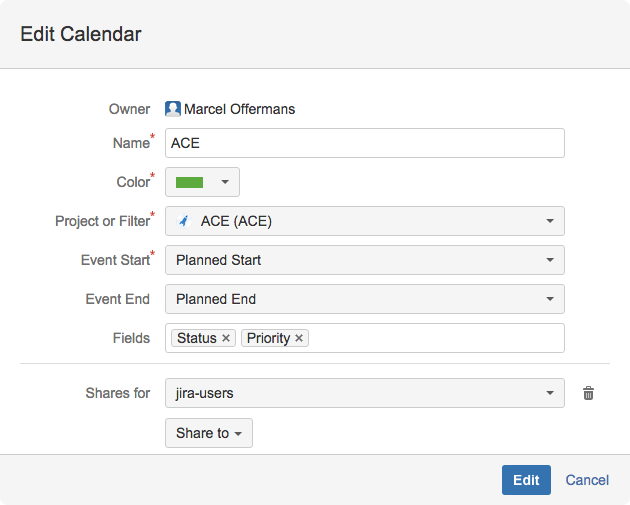
Окно создания/редактирования представляет собой нехитрый набор полей, очевидный для создания календаря. Обязательными там являются только название, источник запросов и начало события. Тут же можете и расшарить календарь на любую доступную вам группу или проектную роль. В правой панели вы можете также управлять видимостью расшаренных на вас календарей. По умолчанию календарь, расшаренный на вас, сперва будет отображен как скрытый. Изменить это можно щелкнув на него. Цветной квадрат означает видимый календарь, цветная рамка — невидимый.
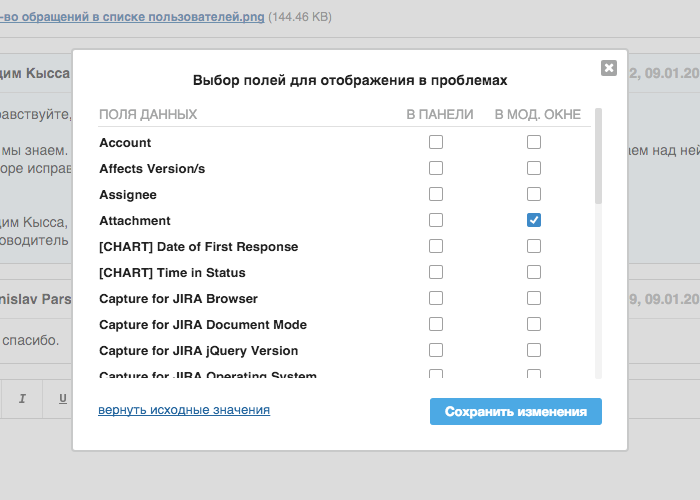
В левой панели располагается сами события. В качестве основы для отрисовки issues мы решили воспользоваться jQuery плагином Full Calendar. В самих event-ах мы видим только issue summary, но если щелкнуть по каждому, то в отдельном popup-е откроется информация по issue с возможностью перехода к этому issue.
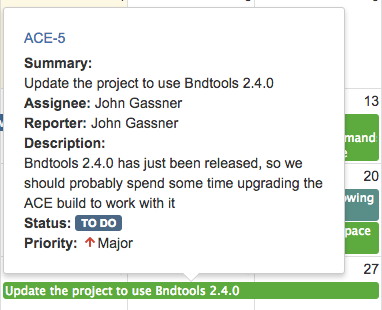
Существуют поля, которые отображаются в этом popup-е по умолчанию: исполнитель, автор и описание issue. Остальные поля вы, как автор календаря, можете настроить в поле «Поля» окна создания/редактирования календаря. Event-ы можно перемещать и растягивать, если у вас есть право на изменение соответствующего issue в JIRA, и в качестве полей «Начало события» и «Конец события» не заданы такие значения как «Создан», «Обновлен» и «Решен», что соответствует дате создания, дате последнего редактирования и дате решения issue соответственно.
Техническая частьНа frontend-е мы использовали один из последних AUI, о котором рассказывали в одном из предыдущих постов. С одной стороны, довольно удобно использовать все самые новые компоненты из библиотеки AUI, c другой, довольно хлопотно обеспечить при этом хорошую обратную совместимость. Допустим, Inline Dialog 2 появился не так давно и недоступен в версиях JIRA раннее 6.2. FullCalendar используется для отрисовки самих issue. На backend-e JIRA API + хранение данных в Active Objects. JIRA API позволяет нам строить jql на основе событий, начала и конца событий, проверку доступа к issues и т.д. Active Objects позволяет удобно хранить данные как о самих календарях, так и о предпочтительных настройках пользователя, как, например, какие из расшаренных календарей должны быть скрыты, а какие видимы. Долгое время, мы извлекали и сохраняли эту информацию при помощи класса PluginSetting, прежде сериализируя ее в XML. При последнем изменении календаря решили использовать Active Objects. Во-первых, тут отпала нужда в сериализации, а во-вторых, с Active Objects проще работать.
ЗаключениеМы рассчитываем и дальше дорабатывать этот плагин. В частности, хотим добавить возможность просмотра в popup-е event-а любой Custom Field. Исходный код можно просмотреть на github. Обновленный календарь доступен для версий JIRA 6.3+.
Ищем спикеров на второй Moscow Atlassian MeetupВторник, 08 Сентября 2015 г. 16:10 (ссылка )

5 лет мы развиваем инфраструктуру Mail.Ru Group, используя продукты Atlassian. Все это время мы постоянно сталкивались с дефицитом специалистов по этим продуктам, к тому же сообщество в России практически не развито. Ответы на все вопросы приходилось искать самим, сражаясь с проблемами, трудностями и службой поддержки Atlassian.
Потом, уже собрав немного опыта, мы организовали свою встречу сообщества — Moscow Atlassian Meetup. На нее пригласили коллег из других IT-компаний и выступили сами. Говорили о многом: я показал на живом примере, как автоматизировать работу редакции контентных проектов; Денис Кулябин из IT-Заботы — как интегрировать телефонию с JIRA; Антон Колин объяснил, почему они в Teamlead не внедряют Service Desk, а Андрей Ларионов из ALM Works рассказал, что делать, если JIRA тормозит. Все доклады мы записали на видео и опубликовали на Хабре. Тогда пришло более 100 человек, а еще 200 смотрели трансляцию онлайн.
Теперь мы хотим собрать людей на вторую встречу по продуктам Atlassian (JIRA, Confluence и другим). Это позволит наконец-то наладить профессиональное общение и развивать рынок использования этих продуктов. Мои коллеги регулярно проводят похожие встречи по другим технологиям, и их опыт оказывается очень полезным для участников. Почему бы и нам не сделать это традицией?
Moscow Atlassian Meetup 2: что будет?
Будем снова говорить об интересном и обсуждать наболевшее. Вообще, выступать на IT-тусовках и даже просто посещать их ужасно полезно для саморазвития. Спикеры еще и получают набор весомых бонусов. Например, это возможность:
Кстати, это бесплатно. Наверняка, у вас есть кейсы, которые заинтересуют других. Расскажите о своем опыте, вы нужны российскому сообществу! Даже с минимальным опытом выступлений и вовсе без него отправляйте заявки на участие. Мы развеем страхи и расскажем подробности.
Вторник, 25 Августа 2015 г. 13:36 (ссылка )
Хочу вам кратко рассказать о продукте от Atlassian: JIRA Service Desk
Точнее, о некоторых хитростях, которые сильно улучшают удобство использования продукта, т.к. про сам плагин сейчас уже многие в курсе.
Для хитростей необходимо использовать скрипты в постфункциях, в данном случае это sil-скрипты плагина JJupin. и уметь написать и выполнить (в т.ч. из скрипта) sql-запросы к БД, где JIRA хранит свои данные. По использованию плагина кратко в другой статье: habrahabr.ru/post/222581
JIRA Service DeskПо названию вроде оно и так понятно, для чего этот плагин — для того, чтобы в JIRA реализовать функциональность службы Service Desk
Но на мой взгляд, самое главное — это прием заявок от пользователей в более удобном и красивом дизайне, с использованием отдельного портала под конкретный проект. И неважно, службу сервисдеск вы хотите организовать или просто прием заявок в какой-то проект.
Если же выражаться точнее и шире, то плагин добавляет в JIRA следующую функциональность:
Использовать эту функциональность вы можете как хотите: в полной мере, для реализации приема и обработки заявок службой Service Desk, либо например только выставление уровней SLA, чтобы контролировать своевременность выполнения заявок, поданных обычными способами, либо будете использовать очереди заявок, либо просто удобство портала по приему заявок
По поводу лицензий на JSD есть тонкости: сейчас они требуются только на тех пользователей, кто будет обрабатывать заявки в проектах, в которых включен Service Desk (их называют агентами), без ограничения по количеству подающих заявки. Раньше было по количеству лицензий в JIRA и те и те.
С одной стороны, если у вас всего 2-3 человека обрабатывают заявки, поданные через портал, то это экономно. Но если у вас заявки обрабатывают много пользователей — ну например в режиме, когда все проекты подключены к JSD, принимаются заявки через портал, а обрабатывают их соответственно пользователи этих проектов/отделов, то здесь уже печаль: цена на количество агентов от 15 и выше быстро уходят в космос. Мы успели купить по старой схеме, поэтому проблем нет.
По моему мнению, у этого плагина не хватает еще одного режима работы и лицензирования: использование только в качестве портала для приема заявок, с количеством лицензий равному таковому в JIRA, и соответственно более гуманной ценой. Потому как у нас большинство проектов не используют ничего, кроме портала (ну кое-где используются sla, минимум). Оно конечно, можно и отдельный плагин с порталом, но это еще один портал, что не есть хорошо. Может кто напишет. ) Сам бы написал, да не умею я в этом всем, чего тут нужно
Итак, теперь про хитрости (про использование и настройку самого плагина я начал писать статью, но не закончил, т.к. очень много всего: если будет сильно требоваться кому-то, может и напишу, а пока без оного)
Многообразие полей информацииИтак, мы настраиваем на портале форму для подачи определенного типа заявок. Портал нам дает прекрасную возможность не только указать порядок полей, но и дать им другие названия для экрана подачи конкретного типа заявок — для лучшего понимания пользователя, а также добавить комментарий.
Это все хорошо конечно: для поля «Размер» я для одного типа заявок напишу «Укажите размер диска», а для другого «Размер экрана», поле у меня будет одно, но никто не запутается при подаче заявки, что там должно быть (это простой пример для понимания)
Но проблема в том, что в конечном итоге таких очень уникальных полей для самой разной информации может быть не один десяток, а то и сотни. И даже если какие-то поля использовать для разных типов заявки, но для похожей информации, количество реальных полей в JIRA не сильно уменьшится. А теперь представьте себе бедного администратора, который должен завести эту кучу полей — причем делать это постоянно, т.к. проекты растут, добавляются и т.д. Не можете представить? Я тоже, лучше и не надо :)
Он конечно с ограничениями: если вам какие-то поля (желательно большинство таких специфичных) нужны дальше только для информации и вам не надо их редактировать по отдельности (ну подали заявку, где 15 полей описывают какие-то параметры, вы их прочитали, поняли и сделали работу, больше ничего), то мы весело решаем эту проблему. Администратор нам должен до конца жизни, ему останется только изучить плагин jjupin и чуть-чуть sql, и совместно с вами уговорить руководство купить этот плагин
Тонкости и проблемы
Для строковых, текстовых и прочих полей, в которых нет предварительно заполненной информации, проблем нет вообще
А вот для разных списков мы имеем проблемы: заполненное значение у поля может быть разным только в разрезе проектов (конфигурация поля), внутри проекта значение для всех типов заявок будет одинаковым. В этом случае, если в одном проекте в разных заявках используется несколько таких уникальных полей, то их придется делать именно такое количество: UniversalFieldListBox01, UniversalFieldListBox02 и т.д. Спасает то, что в других проектах их можно использовать без проблем со своими значениями
Итак, создаем sil-скрипт указанный ниже и вызываем его при создании заявки (этот код можно поместить в отдельный модуль в качестве функции и использовать ее вызов из других скриптов, чтобы не писать под каждый проект)
У нас JIRA работает на MS SQL Server, sql в скрипте под него, если у вас другая БД, то возможно придется немного поменять синтаксис
Ура, все работает!
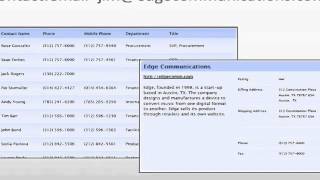
Выглядит результат примерно так (это поле «Описание» в заявке):
[Из песочницы] Интеграция Jira и Slack на PHPПонедельник, 13 Июля 2015 г. 15:59 (ссылка )
Недавно по наводке одного товарища стали в компании использовать Slack. Тут же встал вопрос об интеграции его с Jira. Надо сказать, что Slack номинально имеет интеграцию с Jira из коробки, однако на поверку оказалось, что она обрабатывает далеко не все события, никак не настраивается и вообще работает не так, как хотелось бы. Поэтому было принято решение написать свою интеграцию на php.
Требования были сформированы следующим образом:
Была предпринята попытка найти готовый обработчик запросов от JiraWebHook и адекватные php-классы для работы с SlackAPI. Однако ни одно решение не понравилось и было принято решение сделать все полностью самостоятельно.
Что получилось – собственно, вот
Теперь пару слов о том, что внутри.
Все состоит из трех классов:
Вот, собственно, и все. Возможно это кому-то понадобится. Буду рад замечаниям-дополнениям.